Citation with persistent identifier:
Carless Unwin, Naomi. “What’s in a name? Linguistic considerations in the study of ‘Karian’ religion.” CHS Research Bulletin 4, no. 2 (2016). http://nrs.harvard.edu/urn-3:hlnc.essay:CarlessUnwinN.Linguistic_Considerations.2016
https://youtu.be/Eplwx5WnZno
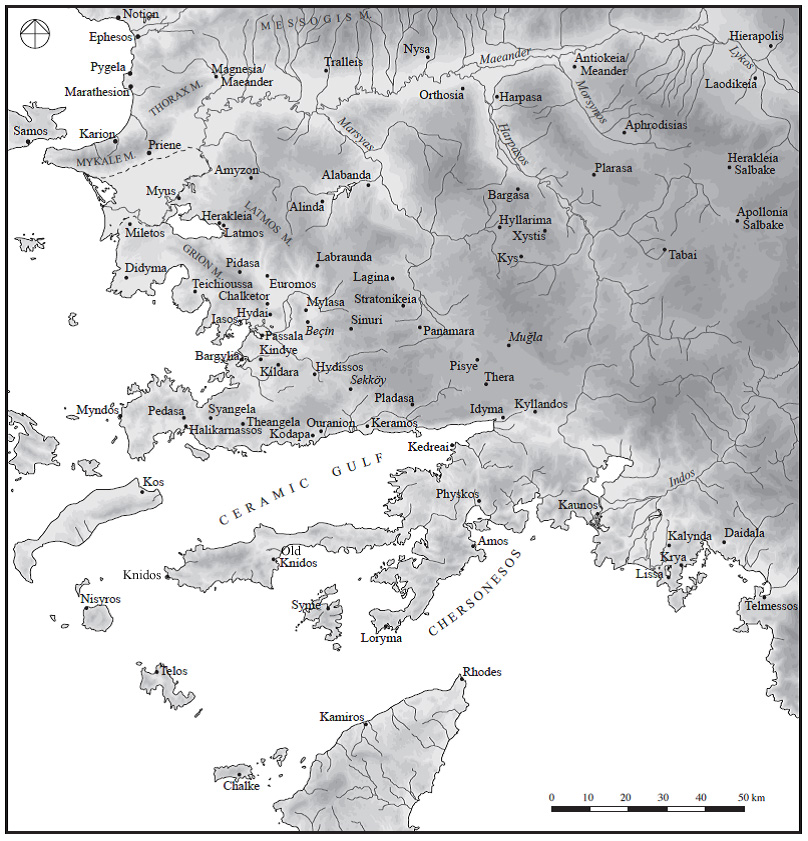
1§1 The history of Karia is entangled with that of the Greek-speaking world; the cultural and religious character of the region was shaped by sustained interaction with both east and west.[1] Ionian and Dorian settlements were established along the Anatolian seaboard from the tenth century BCE onwards, and over the subsequent centuries there was sustained contact and assimilation between the “Karian” communities of the interior and the “Greek” cities along the coast. Geographically, Karia was recognised in antiquity as the area south of the Maeander River, extending east to the Salbakos Mountains (Map 1); it shared borders with Lydia to the north, Phrygia to the east, and Lykia to the southeast. As an ethnos, the “Karians” are more difficult to define; while the Karian language has now been identified as an Indo-European language of the “Luwic” subgroup, related to other Anatolian languages including Luwian and Lykian,[2] identifying this population in the archaeological record remains problematic. The cultural coherence of the region as a whole is also not assured; the limit of Karia as a geographical unit seems to have been greater than the area traditionally inhabited by the “Karian” people, who are thought to have been concentrated in the southwestern area.[3]
1§2 This paper will focus on one aspect of the cultural complexities of the region: that of language, and the role it plays in our interpretation of regional religious practices. The vast majority of our evidence concerning the history and culture of Karia has been transmitted in Greek, with the result that a “Karian” narrative of regional dynamics remains difficult to reconstruct.[4] The Karian language itself disappears from the written record at some point in the third century BCE; though already in the fourth century BCE the majority of public inscriptions in the region are composed in Greek. It can be presumed that a level of bilingualism among sectors of the Karian population was well established before this time.[5]
1§3 In the religious realm, I want to consider how the decline of the Karian language may have affected the practice of Karian cults, and what happened to local deities when they came to be identified with the gods of the Greek pantheon. I will first examine the evidence we possess for the articulation of deities in the Karian language. This remains a growth area and the identifications are tentative; however, such a survey of the modern state of scholarship provides an important corrective to the dominance of the Greek source material. I will then consider the different strategies adopted in the process of assimilation. The implications of this ostensible process of ‘Hellenization’ of Karian deities for how we study “Karian” religion will then be briefly discussed, considering how gods were conceptualised among the ancients and what happened when a god was identified by more than one name. The intention is to bring Karia and the Karian perspective into focus in discussion of the religious dynamics of the region during the Classical and Hellenistic periods; in short, to develop a framework in which the study of “Karian” religion can be fruitfully advanced.
Identifying “Karian” Gods
2§1 Our understanding of the Karian language has increased immeasurably over the last two decades, and the Adiego-Ray-Schürr decipherment is now widely accepted.[6] This enables us to identify personal names and certain case endings,[7] and attempt translations of some individual words.[8] It has also made it possible to suggest identifications of the names of gods rendered in the Karian script, offering a valuable insight into the practice of religion in the native tongue.
2§2 The majority of texts in the Karian language are from private contexts, primarily funerary or religious; in the case of the latter, it is possible to suggest a votive context for certain texts, and through comparison with the names of deities in other Luwic languages, make suggestions as to the identity of the gods honoured. A votive inscription on the rim of an Attic black figure krater, dated to the last quarter of the sixth century BCE, was discovered in the sanctuary of Zeus Megistos and Hera in the coastal city of Iasos:[9]
] areš | šanne | mλne | siykloś |šann | trquδe | k̂λmυδ [
2§3 I. J. Adiego has identified areš and siykloś (in the genitive) as personal names, perhaps that of the dedicator with his patronym.[10] More interesting for our purpose is the name trquδe, which can be connected with Tarhunt-, the Anatolian storm god (Hittite: Tarhu-; Cuneiform Luwian: Tarhunt-; Lykian: Trqqñt-).[11] I.J. Adiego speculates that the following word, k̂λmυδ, could be an epithet for the god.[12] The krater thus seems to be an offering to the Karian god trqude, which would appear in the dative.[13] The same deity appears in another text from Kildara, which was inscribed on a stone also bearing a Greek honorary decree: the word trqδimr appears in the second line.[14] In this case, while the god’s name appears in the sequence, it is not possible to establish the context or even determine the structure of the word; it is not known if it refers solely to the god, or is the name of a person or place.[15]
2§4 The god’s name is again attested in the Hyllarima inscription, dated to the early third century BCE, where the sequence armotrqδosq appears in line 2 of Column A.[16] It is a compound form, containing the names of two Anatolian deities: the storm god trqd- and the moon god armo- (related to the Hittite and Luwian Arma-).[17] I.J. Adiego suggests that it is a ‘dvandva’ compound of two gods, ‘Arma + Tarhunt’[18]; C. Melchert prefers to read it as a theophoric personal name derived from the two deities.[19] The root of the Karian name for the moon god would thus be armo-; though at this point in time, this text is the only secure form to include the deity.[20]
2§5 A further identification has been proposed between the Karian ntro- and the Greek Apollo. This Karian sequence occurs in two texts: the first in an inscription on a lion of Egyptian origin, where the deity’s name appears in the first line as ntros: prŋidas;[21] the second in a text on a bronze phiale, discovered in Karia, where the name appears as ntro.[22] Again, the basis for this identification derives from parallels in other Luwic languages; in particular, the Greek-Lykian-Aramaic trilingual inscription from Xanthos, dated to 337 BC, records the theophoric name Apollodotos in the Greek, which corresponds to Natrbbiyēmi in the Lykian version. [23] Natr- is thus identified as the Lykian deity that came to be assimilated with Apollo.[24] This may find corroboration in the occurrence of the word natri on the north side of the Xanthos stele;[25] in one instance it appears with the epithet turaχssali,[26] which has been tentatively connected with Thyrxeus,[27] the epithet of Apollo at the oracle of Kyaneai as recorded by Pausanias.[28]
2§6 The occurrence of the sequence ntro- in Karian can thus be credibly interpreted as the name of the deity commonly equated with the Greek Apollo. In the Egyptian text E. xx. 7, the sequence ntros: prŋidas appears to be in agreement; D. Schürr has suggested that prŋidas may be connected to Βρανχίδαι, the name of the priests of the sanctuary of Apollo at Didyma.[29] If this is the case, it could be connected with an affiliate sanctuary of Apollo Didymeus that was established in Egypt during the Archaic period; Herodotus writes that the Milesians founded a sanctuary to their own Apollo at Naukratis,[30] while there are epigraphic attestations for both Apollo Milesios and Apollo Didymeus during the Archaic period.[31]
2§7 The second occurrence of ntro was discovered on a phiale from Karia, and has also been interpreted as a dedicatory inscription:
šrquq | qtblemś | ýbt | snn | orkn | ntro | pjdl[32]
2§8 The initial sequence šrquq qtblemś has been identified as a name in the nominative, ‘Šrquq (son) of Qtblem’, which could be that of the dedicator.[33] C. Melchert has suggested that ýbt should be the verb, related to the Lykian ubete, ‘he offered’, while snn orkn would be the direct object, something like ‘this phiale/bowl.’ He further proposed a connection between pjdl and Luwian piya-, and Lykian pije-, meaning ‘to give’; he thus suggested that pjdl was a noun, meaning ‘gift.’[34] The possible sense of the text could consequently be something along the lines of ‘Šrquq (son) of Qtblem offered this bowl to (the Karian god equated with) Apollo as a gift’[35]; this remains the only text for which a full translation has been proposed.[36]
2§9 I. J. Adiego has tentatively identified the presence of another deity in a Karian text from Sinuri, where the sequence añmsñsi occurs.[37] He suggests that it should be separated into añ msñsi, and could be related to the Luwian anniš mašsanaššiši, meaning ‘mother of the Gods’; another parallel is found in the Lykian [ĕ]ni mahanahi.[38] The Karian sequence mso-, or something similar, would therefore be the word for ‘god’, connected with Cuneiform Luwian màššan(i)-, Lykian maha(na)-, and Milyan masa-.[39]
2§10 No further direct attestations of the names of Karian deities in the Karian script have been proposed at this time; however, further insight is offered by onomastics. As noted above, the Lykian name Natrbbiyēmi was translated into the Greek as Apollodotos, thus offering an insight into the Lykian name of Apollo.[40] There is no evidence in Karia as yet for such a direct translation of a personal name between the two languages, though the evidence suggests that ‘double-naming’ occurred; Adiego has noted the dominance of indigenous names in Karian inscriptions, whereas Greek texts that are thought to be contemporary reveal a mixture of onomastics, with the frequent transliteration of Karian names.[41] The implication is that some individuals bore both Greek and Karian names in the respective languages.[42]
2§11 Theophoric personal names can offer clues as to the name of the Karian deity from which they are derived. Returning to the possible rendering of the moon gd as armo- in Karian, Adiego has noted the direct correspondence between the Greek name Μηνόδωρος and the Luwian Armapiya, which in turn seems to be reflected in the Greek transliteration of a Karian name, Ερμαπις.[43] The occurrences of the personal names ktais and ktmnos in the Karian language also seem to confirm the significance of the goddess Hekate in the native tongue.[44] They were rendered in Greek as Hekataios and Hekatomnos, and suggest that the goddess was recognised under a phonetically similar nomenclature in both languages.[45]
2§12 Evidence for the practice of religion in the Karian script will increase with the discovery of further texts and as our understanding of the language improves. The tentative identifications of the names of Karian deities that can be made indicate a strong connection with the names of gods in the other Luwic languages. As yet, it is not possible to propose secure parallels between particular cults attested in Greek and the Karian evidence, though it is known that the identification of local Karian deities with those of the Greek-speaking world took place. The intricacies of this process of ‘contact syncretism’ are difficult to establish,[46] though it can be presumed that overlaps in attributes and myths were sought; thus the storm god rendered in Luwian as Tarhunt seems to have been considered a close match with Zeus. But the religious landscape was much more varied, with numerous local cults distinguished by particular attributes and characteristics; epithets marked the distinctive identities of local cults, and there were a number of strategies by which the rendering of Karian gods in Greek sought to preserve this individuality.
Strategies of Assimilation
3§1 When writing of the Karian sanctuary at Labraunda, Herodotus records that it was known as ‘the precinct of Zeus of the Army’ (Διὸς στρατίου ἱρόν);[47] according to him, ‘the Karians are the only people we know of’ who sacrifice to this deity.[48] The identification of the god worshipped at Labraunda as Zeus is confirmed in the fourth century, when dedications to Zeus Labraundos were made by the native Hekatomnid dynasts.[49] The decision by the Karian dynasts to inscribe such dedications in Greek is instructive, and again reflects the bilingual tendencies that were well established among Karian communities by the fourth century BCE. It is less clear at this stage whether the cult of Zeus Labraundos was considered the same as that of Zeus Stratios. Herodotus’ account implies that the two deities were coterminous; Strabo also notes that Labraunda contained ‘an ancient shrine and statue of Zeus Stratios.’[50] The epithet Stratios could thus refer to the warlike character of the god, whose attribute was the double axe. The epigraphic material, on the other hand, suggests that Zeus Labraundos was the preferred mode of addressing the deity within the sanctuary, and was the title by which the cult was known in the region more broadly.[51]
3§2 The Karian rendering of the deity worshipped at Labraunda is not known, though it is possible that it was a variant of Trqd-, the Karian name for the storm god. In the process of identification with the Greek god Zeus, the local particularity of the cult was distinguished by its cult epithet; in the case of Zeus Labraundos, the primary epithet was toponymic, related to the name of the sanctuary itself. This was a common strategy employed in Karia; for instance, we can note the cult of Zeus Panamaros of the sanctuary of Panamara, or the cults of the different tribes of Mylasa;[52] thus the Greek name for the deity was combined with a Karian geographical name, apparently transliterated into Greek. The epithet in the cult of Zeus Stratios, on the other hand, reflects something of the character of the deity, namely its warlike character. The association of both cult titles with the deity worshipped at the sanctuary of Labraunda raises the possibility that different strategies of assimilation could be employed in different contexts in reference to the same cult.
3§3 This apparent flexibility in the process of assimilation can also be identified in the different names adopted in the Greek language for the primary deity of Mylasa. The most common name in both epigraphic and literary sources is Zeus Osogō. The epithet is Karian in origin, and may be related to the name of the deity in Karian; Pausanias, albeit writing in the second century CE, records that a sanctuary found at Mylasa was dedicated to a god ‘called in the native voice Osogōa’.[53] Pausanias includes this detail in the context of a story told about the Mylasan sanctuary, which relates that sea-water was known to rise up at the site, despite its distance from the sea; this tale can also be traced in the imagery of the cult, with Hellenistic civic coinage from Mylasa depicting the deity carrying a trident.[54] The maritime association of the cult is further strengthened in a series of inscriptions of Roman date, which make reference to Zeus Osogōllis Zenoposeidon;[55] Osogōllis was apparently another rendering of the Karian name of the deity. The cult of Zenoposeidon is attested earlier, in the late third century BCE/early second century BCE, in a series of decrees voted by the cities of Krete for Mylasa, where it is stipulated that the texts should be inscribed in the sanctuaries of both Zenoposeidon and Zeus Labraundos. It is assured that the sanctuary of Zenoposeidon should be equated with that of Zeus Osogō: apparently Zenoposeidon served as another Greek rendering of the Karian deity Osogō at this time.[56] It also seems to indicate that the process of assimilation resulted in sometimes uncomfortable fits; in the case of Zeus Osogō, the clear maritime associations of the cult were not natural to Zeus, which can serve to explain why the title of Zenoposeidon was devised in Greek as a more accurate approximation.
3§4 The processes by which the gods of Karia were assimilated with those of the Greek-speaking world were various, and different strategies could be employed in different contexts, revealing a certain level of fluidity. It can be supposed that Karian speakers continued to call their deities by their native names as long as Karian was spoken; they remained in circulation concurrently with the Greek names, and apparently without any confusion among worshippers about their inherent unity. In other instances, assimilation does not seem to have been attempted, with the transliteration of the Karian name into the Greek script; thus the worship of the god Sinuri continued into the Hellenistic period;[57] a newly published inscription from Pidasa, dated to the late fourth century BCE, further attests to the existence of a previously unknown Karian theonym, Toubassis.[58]
3§5 The initial process of assimilation between Karian and Greek deities, where it was attempted, does not seem to have fundamentally altered how the deity was conceived. The dedication to trquδe from Iasos was discovered in the sanctuary of Zeus Megistos; it is possible that the deity addressed was the Karian rendering of the same god. Similarly, if the deity ntros prŋidas can be equated with Apollo Didymeus, it should be supposed that the worshippers perceived the deity to be the same, whether the deity was addressed in Karian or in Greek.
Practicing Religion on the Interface
4§1 The transmission of the majority of our information in Greek has wide repercussions for the study of religion in Karia, and we need to be wary of the potential distortion that results. As discussed, the majority of Karian cults are only attested in their Greek forms; however, this need not have made them more ‘Greek’ than ‘Karian.’ In Karia, linguistic contact was regular and bilateral, and it is possible to envisage that the syncretistic process began early. The gradual dominance of the Greek language among the communities of Karia did not automatically create conformity between cultures, nor did it lead to the loss of an awareness of regional history. Exploration of the strategies employed in the process of assimilation reveals that the identification of local gods with the Greek pantheon preserved the fundamentally local character of the cults. Karian divine names may have eventually disappeared as the Karian language itself declined in usage; but the process was gradual, and we can envisage the coexistence of divine names for a number of generations. Local cults remained rooted in the local landscape, and even when their practice was articulated in Greek, their association with the Karian history of the region is marked.
4§2 Ancient conceptions of the divine permitted a great degree of accommodation and variation between peoples; the identification of Greek gods with those of foreigners is a frequent motif in our literary sources, notably Herodotus.[59] The process was likely never exact, and permitted local idiosyncrasies, but at a fundamental level there seems to have been no difficulty in the ancient world for peoples to accept that the same deity could appear in different guises and under different names.[60] Even within the pantheistic traditions of the Greek-speaking world, the multiplicity of local cults, individualised by their epithets, were accommodated within the established divine framework known from literature, and apparently with no problems of understanding on the part of the adherents as to the identity of the deity concerned;[61] indeed, apparent inconsistencies and the lack of an underlying coherence are not questions that seem to have concerned the ancients to the same degree as modern scholars, even, for instance, when they invoked the authority of different cults of Zeus simultaneously.[62]
4§3 The accommodation of local particularities within a wider religious framework was not unique to the Greeks; indeed, the frequent attempts to make sense of foreign deities within a Hellenic framework reveal that such adjustment extended to non-Greek populations. In the case of Karia, the communities of the region were not of remote interest to the Greek-speaking cities of the coast, but were integrated into their networks for as long as we can trace their history. Syncretism arose in this environment as a natural by-product of long-term contact and integration between different language communities. The study of religion in Karia thus needs to focus on these local religious dynamics, and any notion of ‘Karian’ religion should not be considered in isolation from the religious history of their Greek neighbours. The naming of the gods in both Greek and in Karian reveals that the cults and mythologies of Karia could be incorporated into the wider Greek framework without undermining local, and sometimes explicitly Karian, religious identities.
Bibliography
Adams, J.N., and S. Swain. 2002. “Introduction.” In Bilingualism in Ancient Society: language contact and the written word, ed. J. N. Adams, M. Janse and S. Swain, 1-20. Oxford.
Adiego, I.-J. 1994. “El nombre cario Hecatomno.” CFC (Estudios griegos e indoeuropeos) n. s. 4:247–256.
———. 2007. The Carian Language. Brill.
———. 2010. “Recent Developments in the Decipherment of Carian.” In Hellenistic Karia, ed. van Bremen and Carbon 2010:147-176.
———. 2013.“Carian Identity and Carian Language.” In Henry 2013:15-20.
Adiego, I.- J., P. Debord, and E. Varinlioğlu. 2005. “La stele caro-grecque d’Hyllarima (Carie).” REA 107, no. 2:601-653.
Allan, W. 2004.“Religious Syncretism: The New Gods of Greek Tragedy.” Harvard Studies in Classical Philology 102:113–155.
Bernand, A. 1970. Le delta égyptien d’après les textes grecs I 2. Cairo.
Blümel, W. 1990. “Zwei neue Inschriften aus Mylasa aus der Zeit des Maussollos.” EA 16:29–43.
———. 1992. “Einheimische Personennamen in Griechischen Inschriften aus Karien.” EA 20:7-34.
Blümel, W., and I.-J. Adiego. 1993. “Die karische Inschrift von Kildara.” Kadmos 32:87–95.
Bresson, A. 2007. “Les Cariens ou la mauvaise conscience du barbare.” In Tra Oriente e Occidente. Indigeni, Greci e Romani in Asia Minore, ed. A. Bresson and G. Urso, 209-228. Pisa.
Brun P., L. Cavalier, K. Konuk, and F. Prost, eds. 2013. Euploia. La Lycie et la Carie antiques. Dynamiques des territoires, échanges et identities. Bordeaux.
Brun, P. et al. 2015.“Pidasa et Asandros: une nouvelle inscription (321/0).” REA 117, no. 2:371-409.
Bryce, T. R. 1986. The Lycians in Literary and Epigraphic Sources. Copenhagen.
Burgin, J. 2010. “A Geographical Note on the Xanthos Stele.” Kadmos 49:181-186.
Carbon, J.-M. 2012. Mixobarbaroi: epigraphical aspects of religion in Karia (6th– 1st centuries BC). PhD diss., Oxford.
Collins, B.J., M.R. Bachvarova, and I.C. Rutherford, eds. 2008. Anatolian Interfaces. Hittites, Greeks and their Neighbours. Oxford.
Colvin, S. 2004. “Names in Hellenistic and Roman Lycia.” In The Greco-Roman East, ed S. Colvin, 44-84. Cambridge.
Debord, P. 2001. “Sur quelques Zeus cariens: Religion et Politique.” In Studi Ellenistici, ed. B. Virgilio, 13:19-37. Pisa.
———. 2013. “Hécate, divinité carienne.” In Brun, et al. 2013: 85-92.
Delrieux, F. 1999. “Les monnaies de Mylasa aux types de Zeus Osogôa et Zeus Labraundeus.” NC 159:33-45.
Fraser, P.M. 1970. “Greek-Phoenician Bilingual Inscriptions from Rhodes.” ABSA 65:31-36.
Henry, O., ed. 2013. 4th Century Karia: Defining a Karian Identity under the Hekatomnids. Paris.
Herda, A. 2008. “Apollon Delphinios – Apollon Didymeus: Zwei Gesichter eines milesischen Gottes und ihr Bezug zur Kolonisation Milets in archaischer Zeit.” In Kult(ur)kontakte. Apollon in Milet/Didyma, Histria, Myus, Naukratis und auf Zypern, Akten der Table Ronde in Mainz, ed. R. Bol, et al., vom 11.–12: 13–85. Marz 2004. Rahden.
———. 2013.“Greek (and our) Views on the Karians.” In Luwian Identities. Culture, Language and Religion between Anatolia and the Aegean, ed. A. Mouton, I. Rutherford, and I. Yakubovich, 421-506. Leiden.
Herda, A., and E. Sauter. 2009. “Karerinnen und Karer in Milet: Zu einem spätklassischen Schüsselchen mit karischem Graffito aus Milet.” Archäologischer Anzeiger 51-112.
Heygi, D. 1998. “The Cult of Sinuri in Caria.” Acta. Ant. Hung 38:157-163.
Hornblower, S. 1982. Mausolus. Oxford.
Hornblower, S., and E. Matthews, eds. 2000. Greek Personal Names: Their Value as Evidence. Oxford.
Laumonier, A. 1958. Les cultes indigènes en Carie. Paris.
Lebrun, R. 2009. “Les permanences culturelles louvites dans la Lycie hellénistique.” In L’Asie Mineure dans l’Antiquité. Échanges, populations et territoires, ed. H. Bru, F. Kirbihler, and S. Lebreton, 379-388. Rennes.
Malkin, I. 2005. “Herakles and Melqart: Greeks and Phoenicians in the Middle Ground.” In Cultural Borrowings and Ethnic Appropriations in Antiquity, ed. E. S. Gruen, 238-257. Stuttgart.
Masson, O. 1988. “Le culte ionien d’Apollon Oulios d’après des données onomastiques nouvelles.” Journal des Savants Vol. 3, No. 1: 173-183.
Melchert, H. C. 1993.“Some Remarks on New Readings in Carian.” Kadmos 32:77-86.
———. 2002. “Sibilants in Carian.” In Novalis Indogermanica, Festschrift für Günter Neumann zum 80. Geburtstag, ed. M. Fritz and S. Zeilfelder, 305-313. Graz.
———. 2003. “Language’ in The Luwians.” In The Luwians, ed. H.C. Melchert, 170-210. Leiden.
———. 2010. “Further thoughts on Carian Nominal Inflection.” In van Bremen and Carbon 2010:177-186
Mikalson, J.D. 2003. Herodotus and Religion in the Persian Wars. Chapel Hill.
Mountjoy, P.A. 1998. “The East Aegean-West Anatolian Interface in the Late Bronze Age: Mycenaeans and the Kingdom of Ahhiyawa.” Anatolian Studies 48:33-67.
Mullen, A. 2012. “Introduction. Multiple Languages, multiple identities.” In Multilingualism in the Graeco-Roman Worlds, ed. A. Mullen and P. James, 1-35. Cambridge.
Osborne, R. 2012. “Cultures as languages and languages as cultures.” In Mullen and James 2012:317-334.
Parker, R. 2000.“Theophoric Names and the History of Greek Religion.” In Hornblower and Matthews 2000:53-79.
———. 2003. “The Problem of the Greek Cult Epithet.” Opuscula Atheniensia 28:173-183.
Piras, D. 2009. “Der archäologische Kontext karischer Sprachdenkmäler und seine Bedeutung für die kulturelle Identität Kariens.” In Rumscheid 2009:229-250.
Popko, M. 1995. Religions of Asia Minor. Warsaw.
Rudhardt, J. 1992. “De l’attitude des Grecs a l’égard des religions étrangères.” Revue de l’histoire des religions 209, No. 3:219-238.
Rumscheid, F., ed. 2009. Die Karer und die Anderen. Internationales Kolloquium an der Freien Universität Berlin 13 bis 15 Oktober 2005. Bonn.
Rutherford, I. 2006. “Religion at the Greco-Anatolian Interface. The Case of Karia.” In Pluralismus und Wandel in den Religionen im vorhellenistischen Anatolien. Akten des religionsgeschichtlichen Symposiums in Bonn (19.-20, Mai 2005), ed. M. Hutter and S. Hutter-Braunsar, 137-144. Münster.
Salmeri, G. 1994. “I Greci e le lingue indigene d’Asia Minore: it case del cario.” In La decifrazione del cario, ed. M. Salvini, 87-99. Rome.
Schürr, D. 1998. “Kaunos in lykischen Inschriften.” Kadmos 37:143-162.
Steele, P. M. 2013. A Linguistic History of Ancient Cyprus. The Non-Greek Languages, and their Relations with Greek, c. 1600 – 300 BC. Cambridge.
Ulf, C. 2009. “Rethinking Cultural Contacts.” Ancient West and East 8:82-132.
Van Bremen, R., and J.-M. Carbon, eds. 2010. Hellenistic Karia. Bordeaux.
Versnel, H.S. 2011. Coping With the Gods. Wayward Readings in Greek Theology. Leiden – Boston.
[1] See Ulf (2009), esp. 95ff.
[2] Adiego (2007), 4 with n. 3, 345-7; Melchert (2003), 175-177.
[3] Carbon (2012) 15. The cultural unity between eastern and western Karia is not assured. The editors of LGPN VB, xxxi-xxxii, note the differences in naming practices in different regions of Karia; in particular, the indigenous names in the eastern region seem to be affiliated more with Phrygia and Pisidia rather than the western region.
[4] While it is known that regional histories were written in antiquity (albeit in Greek), only fragments now remain: Philip of Theangela: FGrH 741 (Strabo 14. 2. 28, l. 25): his work was titled τὰ Καρικὰ; Apollonios of Aphrodisias: FGrH 740 (cf. Suda s.v. Ἀπολλώνιος, Ἀφροδισιεὺς, ἀρχιερεὺς καὶ ἱστορικός. γέγραφε Καρικὰ); Leon of Alabanda: FGrH 278 (cf. Suda s.v. Λέων, Ἀλαβανδεύς, ῥήτωρ. ἔγραψε Καρικῶν βιβλία δ).
[5] When writing of the expedition of Kimon to western Anatolia in the first half of the fifth century BCE, Ephoros (FGrH 70 F 191, frag. 8; Diodorus Siculus 11. 60. 4) distinguished between the coastal foundations that had been settled by Greeks, and those bilingual (δίγλωττοι) communities that still possessed Persian garrisons. Although it is not explicitly stated, it should be presumed he was referring to Karian-Greek bilingualism; though a Persian presence in the region should also be expected in Karia. See now Salmeri (1994).
[6] For the history of the decipherment, see Adiego (2007), Chapter 4.
[7] Melchert (2010); Adiego (2010), esp. 152, 156.
[8] Adiego (2010); see now Adiego (2007) Chapter 11. For instance, it is thought that mno-, ted and en should be translated as ‘son’, ‘father’ and ‘mother’ respectively; Adiego (2007) 272-273. As yet, there are no secure identification of verbs (Melchert (2010) 177), though see the possible interpretation of C.xx 1 by Melchert (1993) below.
[9] C. Ia 3, Adiego (2007) 147-148. See Piras (2009) 233-234.
[10] Adiego (2007) 286; (2010) 173.
[11] Adiego (2007) 286-297, 347, 423; Adiego (2010) 173. This identification was originally suggested in Blümel & Adiego (1993) 94.
[12] Adiego (2007) 287, 378.
[13] Adiego (2007) 286-287; (2010) 171-173. Cf. Melchert (2010) 184.
[14] C.Ki 1, Adiego (2007) 141-142, 309-310; there is no clear evidence for a connection between the two texts.
[15] Adiego (2007) 309-310, 422.
[16] C. Hy 1, Adiego et al. (2005); Adiego (2007) 135-136.
[17] Adiego (2007) 306; (2010) 160.
[18] Adiego et al. (2005) 616-617; Adiego (2007) 355-356; (2010) 160.
[19] Melchert (2010) 185: he compares it to the personal name Armatarḫunta– that appears in cuneiform.
[20] C. Eu 2 (Adiego (2007) 133-134) includes the sequence armon, which may be related to the moon god; Adiego (2007) 309, suggests it could be the accusative of armo-. The same sequence occurs in a Karian-Egyptian bilingual text from Memphis, E. Me 8 (Adiego (2007) 40-41), where it seems to correspond to p3wḥm, the Egyptian word for ‘dragoman’, or ‘interpreter’; Adiego (2007) 355. See below for theophoric names possibly connected with Arma.
[21] E. xx 7, Adiego (2007) 128.
[22] C. xx 1, Adiego (2007) 160.
[23] Colvin (2004) 59; Adiego (2007) 389. See also the Karian personal name Νετερβιμος: Blümel (1992) 22. Cf. Melchert (1993) 80.
[24] Adiego (2010) 171-172. Cf. Melchert (1993) 80; Schürr (1998) 158.
[25] TL 44 C. 33, 47-48.
[26] TL 44 C. 47-48.
[27] See now Bryce (1986) 187; Popko (1995) 173; Schürr (1998) 156; Colvin (2004) 59, n. 28; Lebrun (2009) 387. Cf. Burgin (2010) 184f.
[28] Pausanias 7. 21. 13.
[29] Schürr (1998) 158. Cf. Adiego (2007) 285-286, 389; (2010) 173; Melchert (2010) 183. Herda (2013) 438, (Fig. 7, a-b), suggests it is a dedication to the god.
[30] Hdt. 2. 178.3. Cf. Herda (2008) 39f.; (2013) 438.
[31] Dedications to Apollo Milesios, dated to the sixth/fifth centuries BCE: Bernand (1970) 642, n. 4; 648, n. 61; 649, n. 72; 661, n. 179; 661, n. 180; 662, n. 194; 662, n. 195; 662, n. 198; possibly 671, n. 302; 708, n. 661. Apollo Didymeus is attested in another text, dated to the second third of the sixth century BCE: Bernand (1970) 655, n. 125: [Ἀπόλλω]ν̣ι Διδυ[μεῖ]. Cf. Herda (2008) 39-40.
[32] Cxx. 1.
[33] Adiego (2010) 171, suggests that Šrquq could be related to *Σαρ- + Γυγος, while Qtblem could be Κυτβελημις, Κοτβελημος. Cf. Adiego (2007) 160.
[34] Melchert (1993).
[35] Melchert (1993); Adiego (2010) 171-172.
[36] Originally proposed in Melchert (1993). Schürr (1998), 158, subsequently proposed that ntro was a derivative of the name of Apollo, rather than a direct occurrence of the divine name; supported by Melchert (2002), 309, who suggests as an interpretation ‘Šrquq (son) of Q., dedicated this bowl – the priest of Apollo as a gift’. However, Adiego (2010), 171-172, and Melchert (2010), 183-184, both support the original interpretation of the text as a dedication to a god.
[37] C. Si 2a, line 5, Adiego (2007) 139-141.
[38] Adiego (2007) 352. Cf. Carbon (2012) 179. See n. 8.
[39] Adiego (2007) 385.
[40] The translation of theophoric names is also attested on Rhodes, where a Greek-Phoenician bilingual, dated c. 300 BCE, records the name of an individual from Kition on Cyprus; the Greek rendering, Herakleides, corresponds to Abdelmelqart, ‘servant of Melqart’, in Phoenician (Fraser (1970) no. 1, 31-32; Steele (2013) 211-212). Cf. Osborne (2012) 319f. On the perceived affiliation between Herakles and Melqart, see Malkin (2005). Parker (2000) 67, suggests that in some cases the familiarity of the theophoric name was of greater importance than offering a direct translation of both elements.
[41] For instance, in C. Hy 1; Adiego et al. (2005) 614-615; Adiego (2013) 16f.
[42] Adiego (2013) 16-17; cf. Colvin (2004) 65. Translation was only one procedure by which an individual could articulate his or her name in another language in antiquity; another method was the adoption of ‘flexible names’ that could work in both languages, or bore a ‘formal resemblance’ to one another. Adiego (2013) 17, suggests that the popularity of the Greek name Οὐλιάδης was due to its similarity to the Karian name wliat/wljat, which was transliterated in Greek as Ολιατος/Υλιατος; following an initial suggestion by Masson (1988). Transliteration was also prominent: our knowledge of Karian onomastics derives in large part through their rendering in the Greek alphabet. An extensive list of Karian personal names is provided in Blümel (1992); Adiego (2007), Appendix C. See the discussion of Anatolian names in Adiego (2007) 12-16.
[43] Adiego (2013) 17; see also Bresson (2007) 220, n. 38. Cf. Blümel (1992) 7. It has been suggested that the popularity in western Anatolia of names formed with Μηνο-, apparently connected with the god Men, could be connected to indigenous names derived from the Luwian moon god Arma; Parker (2000) 76-77.
[44] Adiego (1994); (2007) 375.
[45] Debord (2013) 90. Adiego (2007) 375f., has suggested that Hekataios (‘related to Hekate’) could be in origin an approximate translation of Hekatomnos, literally understood as ‘son of Hekate.’ See also Adiego (1994) 254; (2013) 18.
[46] See the useful discussion of syncretism in Allan (2004) 116ff.
[47] Herodotus 5. 119.
[48] Herodotus 5. 119: μοῦνοι δὲ τῶν ἡμεῖς ἴδμεν Κᾶρες εἰσὶ οἳ Διὶ στρατίῳ θυσίας ἀνάγουσι.
[49] I. Labraunda 27 (Hekatomnos); I. Labraunda 13, 14 (Maussollos); I. Labraunda 15-18 (Idrieus). Cf. Hornblower (1982) 240-241.
[50] Strabo 14. 2. 23: ἑνταῦθα νεώς ἐστιν ἀρχαῖος καὶ ξόανον Διὸς Στρατίοι.
[51] Though it should be noted that a priesthood of Zeus Stratios and Hera is attested at Mylasa in the second century BCE: I. Mylasa 204. 16; 405. 3.
[52] The three separate phylai (Otorkondeis, Hyarbesytai, Konodorkondeis) retained their own separate cults of Zeus (e.g. Zeus Otorkondeis). See now Debord (2001) 294. Cf. Laumonier (1958) 30.
[53] Pausanias 8. 10. 4: φωνῆ τῆ ἐπιχωρία καλοῦσιν Ὀσογῶα.
[54] Delrieux (1999) 33–45.
[55] I. Mylasa 319-325, 327; see Blümel (1990) 34.
[56] It was stipulated in a number of Hellenistic Mylasan documents that the texts be displayed in the sanctuaries of both Zeus Osogō and Zeus Labraundos; see I. Labraunda 8b, ll. 24–26; Milet 1. 3. 146a, ll. 18–20; 146b, ll. 72–73.
[57] Carbon (2012) 22, writes that ‘Sinuri is, by name certainly, probably as close as one can get to an indigenous Karian deity, but his principal sanctuary, from all available epigraphical evidence, appears to operate in a relatively standard Hellenic fashion.’ Laumonier (1958) 180-181, considered the cult as a native ‘survival’, and proposed an Anatolian or Near-Eastern origin; cf. 462, where Sinuri is described as a ‘dieu de vieille importation orientale.’ See now Hornblower (1982) 345; Hegyi (1998).
[58] See Adiego in Brun et al. (2015), 404-409.
[59] When discussing Egyptian religion, for instance, he writes that Amun was the Egyptian name for Zeus (2. 42. 5), while Osiris and Isis were the Egyptian equivalents of Dionysos and Isis (2. 42. 2). He is not consistent in his approach to foreign deities, on certain occasions referring to their ‘native’ names, on others simply giving their Hellenic title; thus he writes of visiting a great temple of Herakles at Tyre in Phoenicia, which was actually that of Melqart (2. 44. 1). In his discussion of Babylonian religion, he refers to a temple of Zeus Belos, whereby it is the cult’s epithet that marks its foreign identity and association with the native name Bel (1. 181. 2). Of the Persians, he writes that ‘Zeus in their system is the whole circle of the heavens, and they sacrifice to him from the tops of mountains,’ without mentioning the Persian name (1. 131. 2). The most explicit passage to acknowledge the variations in names between peoples occurs in his discussion of Aphrodite: ‘the Assyrians call Aphrodite Mylitta, the Arabians Alilat, the Persians Mitra’ (1. 131. 3).
[60] Rudhardt (1992) 224, 228; Mikalson (2003) 173.
[61] See now: Versnel (2011) 71ff. On epithets: Parker (2003); Versnel (2011) 60ff.
[62] Versnel (2011) 77ff.: when considering the interplay between the diverse cults of deities and their supposed underlying unity, Versnel develops the notion that ‘they may’ be considered as one, ‘but need not’ be; as he writes (82): ‘To put it provocatively, gods bearing the same name with different epithets were and were not one and the same, depending on their momentary registrations in the believer’s various layers of perception.’ Original Italics.