Persistent identifier: http://nrs.harvard.edu/urn-3:hlnc.essay:KoentgesT.Computational_Analysis_of_the_Corpus_Platonicum.2018
Abstract
The Corpus Platonicum is one of the most well-known and most influential works of ancient literature. Yet, it still has unresolved challenges regarding its tetralogical form and the authorship of some of the works. In addition, tracing its ideas through two millennia of Greek literature requires intimate knowledge of the over 500,000-words-long corpus, but also the reading and manual analysis of several-hundred-million words of Greek. The last decade of Natural Language Processing research, however, has developed promising automated analytical methods to process and classify huge amounts of texts. This research can now be put to use to disclose complex patterns and intratexuality in the Corpus Platonicum and to analyse stylometric patterns in the preponderance of the extant text of the first millennium of Greek literature.
During my residency, I resolved challenges in the data of both the Corpus Platonicum and a corpus consisting of all of the Perseus Digital Library’s (PerseusDL) Greek CTS EpiDoc XML editions and the texts produced in CHS’s First1KGreek-Project. I then applied two big-textual-data methods, topic modeling and stylometric analysis, to the corpora. One preliminary result is that there is little stylistic evidence that the Menexenus was written by the authorial entity we identify as Plato.
Research Goal
To date, digital researchers have only focused on simple function words and co-occurrence analyses within word chunks of fixed word count or in overlapping 5-grams when analysing Plato’s work (e.g. Geßner 2010 and Johnson & Tarrant 2014). While their results have value, it is difficult to connect them with more complex computational research, and analyses that focus on text-inherent logical citation are still research desiderata. Complex computational textual research can be broken down into a number of analysis and synthesis processes. For instance, individual analyses of functional words, co-occurrence of words, topic modeling, metrical analysis, or morpho-syntactical analysis could be combined for clustering or classifying text. Additionally, hypotheses gained through one experiment can be evaluated using other independent data experiments or more traditional analysis. A robust citation architecture (e.g. CTS, developed and used by the Homer Multitext Project) allows us to combine the results of relatively simple analyses into a complex decision pattern that can help to cluster the Corpus Platonicum efficiently, revealing information and producing the statistical basis for decisions regarding authorship and intratexual relations. Because of this, one of the goals of my fellowship was to check and clean the current citation architecture of the Corpus Platonicum. After this, building on topic modeling work that I conducted at the University of Leipzig and Tufts University, my goal was to perform the first thorough multi-method computational analysis of the Corpus Platonicum with the initial intention to use the results of those analytical processes to assist with detecting verbatim and non-verbatim re-use and reception of platonic thoughts and ideas in Latin and Ancient Greek.
Progress & Preliminary Findings
Data Preparation
Although this project build on the immense digitisation efforts of PerseusDL at Tufts University, the Open Greek and Latin project (OGL) at the University of Leipzig, and the CHS, I spent two thirds of my residency on data cleaning and preparation. Within the last 30 years PerseusDL has digitised and curated the preponderance of the Corpus Platonicum and in a move to a CTS-inspired citation, OGL has performed several transformations of the PerseusDL data (e.g. Unicode-Beta-code conversion, an overhaul of the XML-tags, setting Stephanus pages as units within the XML files). This data, however, still needed some semi-manual correction and modification.
First, due to the hierarchical nature of the XML format produced in this digitisation effort, the Stephanus paragraph borders are only preserved in XML-milestones, that is, in boundary points instead of overarching structures that include the individual paragraphs. The overarching hierarchical units in the XML files are Stephanus pages in combination with either speaker tags or logical paragraph tags. PerseusDL made the decision to express logical paragraphs as the primary mode of citation and preserve the Stephanus paragraphs only in XML-milestones, because of the fact that Stephanus paragraphs often break the text mid-sentence, and in the original Stephanus edition even mid-word. Yet, for an easier alignment of the original Greek and the Latin translation, it is important to preserve the Stephanus paragraphs; ideally in a format that somehow preserves both the Stephanus paragraphs and logical units like the change of speaker..
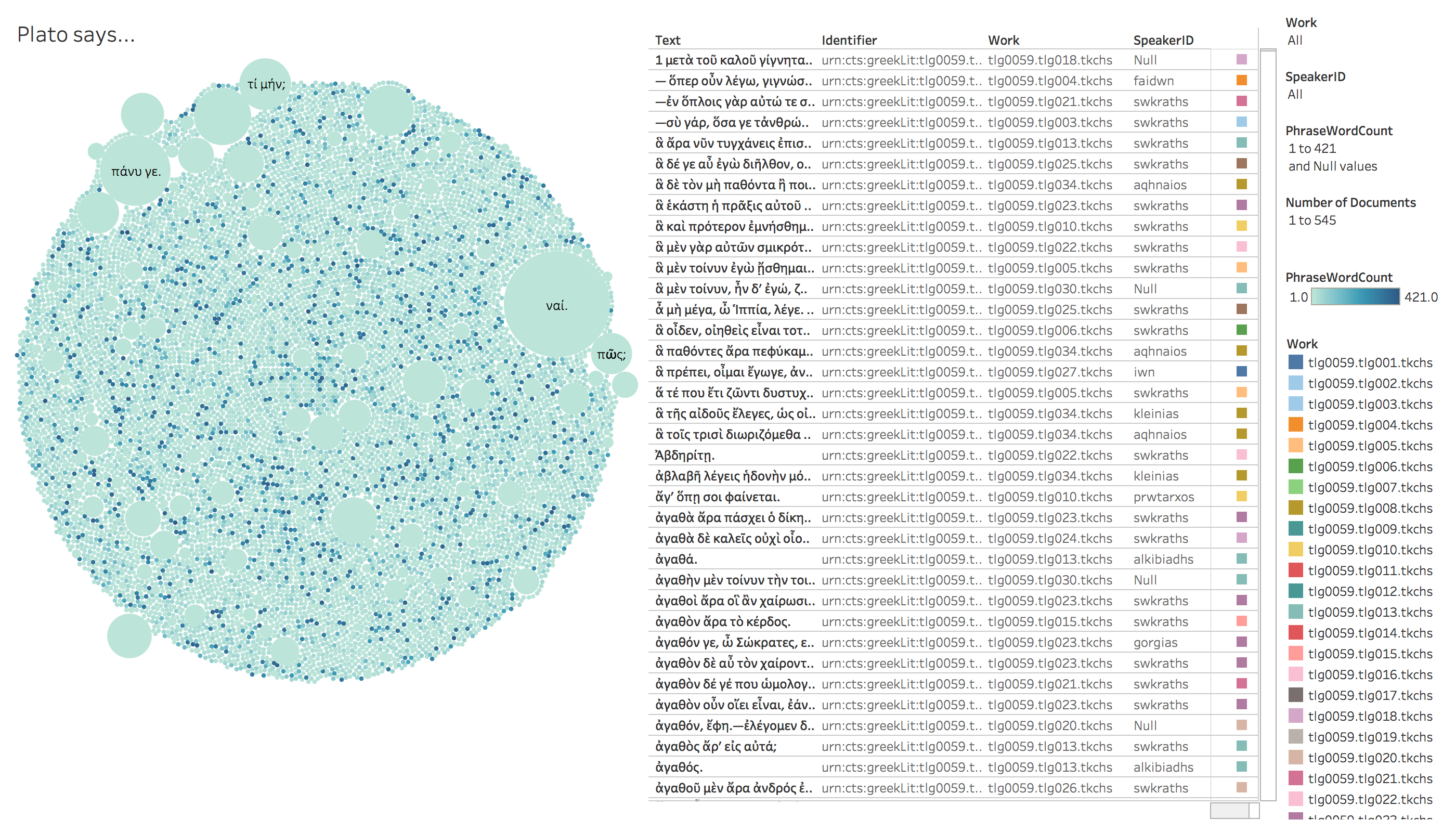
In addition, there were two inconsistencies in the data. I wrote some R-scripts and small GoLang-apps to address those inconsistencies and reformat the data (see Figure 1 on the impact of speaker tags in exploring the Corpus Platonicum). I also had conversations with Lisa Cerrato of the PerseusDL where I highlighted the inconsistencies, which she swiftly addressed. Researchers will now be able to retrieve a cleaner XML file out-of-the-box directly from PerseusDL’s GitHub repository.[1]
While the Greek Corpus Platonicum is now in a format ready for Natural Language Processing (NLP), a Latin translation of the Corpus Platonicum could not be made available and digitised, as hoped, before the residency. After discussions with Dr Jeffrey Witt, editor of the Scholastic Commentaries and Text Archive (SCTA), Aristotle could prove to be a fruitful alternative to Plato in the future, since we have Aristotle’s works in a digital format in both Latin translation and Greek. For the research during my fellowship, however, I had to exclude the analysis of the Latin Corpus Platonicum.
Topic Modeling
After the Greek corpus had been thus prepared for NLP, I performed LDA topic modeling as a first experiment on the roughly 27-million-word research corpus. Topic modeling is ‘a method for finding and tracing clusters of words (called “topics” in shorthand) in large bodies of texts’ (Posner 2012). A topic can be described as a recurring pattern of co-occurring words (Brett 2012). Topic models are probabilistic models that are often based on the number of topics in the corpus being assumed and fixed. The simplest and probably one of the most frequently applied topic models is LDA, the latent Dirichlet allocation (Blei 2012). LDA is a method of statistical inference deducing the properties of an assumed underlying Dirichlet distribution by analysing the words of a corpus. LDA is based on a simplification model of the creation of text in which the word order, for instance, does not matter. It is highly effective in tracing recurring clusters of co-occurring words that may reveal a lot about text-reuse, recurring topics, or the transmission of ideas through time and genres.
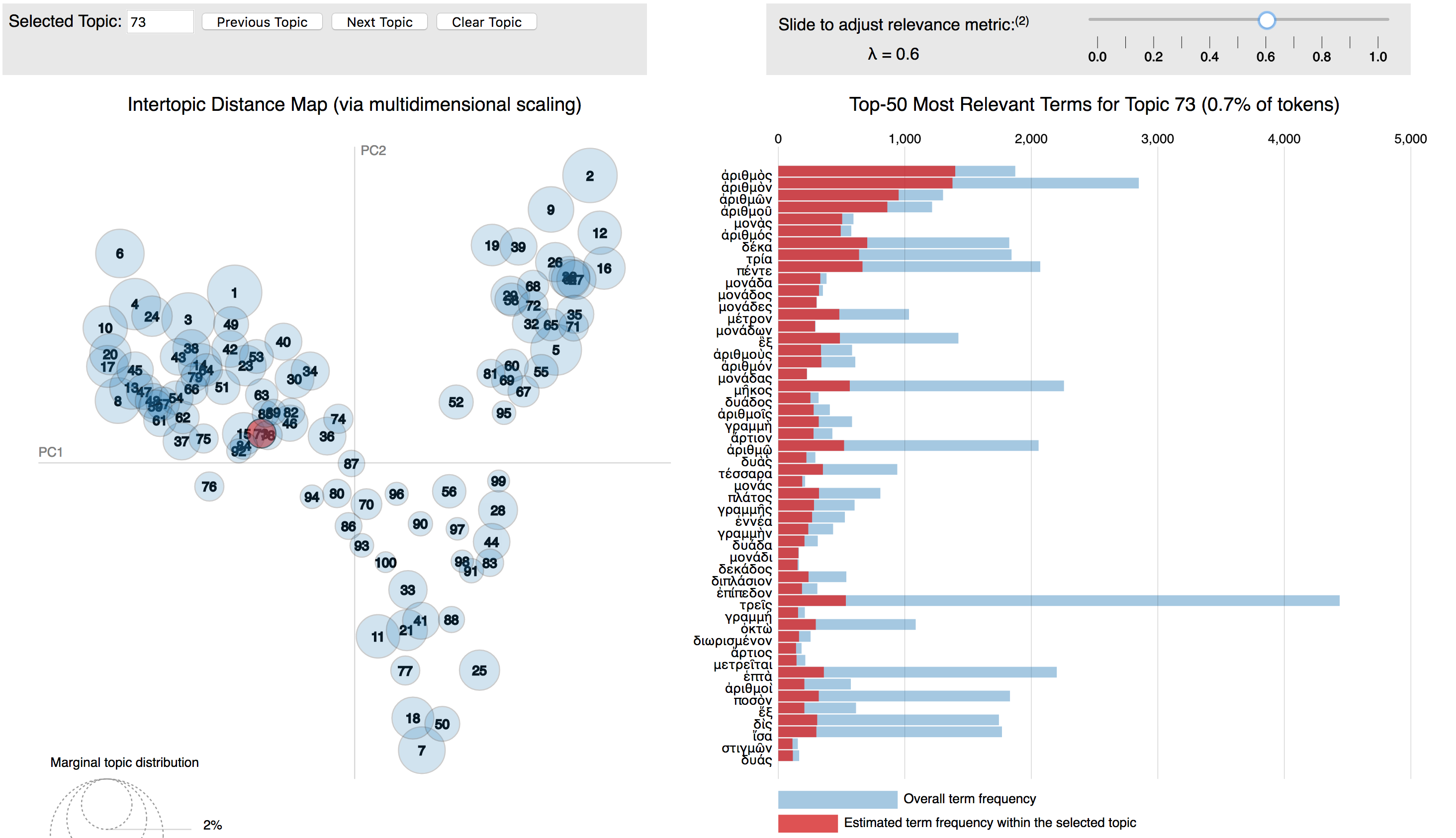
For the task of topic modeling, I used the program Meletē ToPān, which I had developed before visiting the CHS (for an example see Figure 2). When performing LDA on the corpus, however, some of the results regarding the Corpus Platonicum struck me as odd. For example, while the Corpus Platonicum had clear similarities in topic structure across almost all of the works, the Menexenus seemed much more similar in topic structure to Xenophon’s Apology than to Plato’s Apology. I then followed a hunch and also performed stylometric analysis on the corpus to be more certain about the authorship of individual dialogues and while I also wrote a prototype for a non-verbatim text-reuse finding aid, called Metallō, to trace platonic thoughts through Greek literature, the results of the stylometric analysis were so interesting (and gained a lot of attention at the SCS 2018) that I decided to first prepare those for publication, before further pursuing my non-verbatim text-reuse research.
Stylometry
Since the middle of the nineteenth century, stylometry, that is the counting and statistical analysis of features in the language of an author, has been applied to the Corpus Platonicum in order to date the works by Plato, prove or disprove the authenticity of his work, or a combination of the two. The results were inconclusive. One probable reason for this lies in the selection of features and the number of features extracted: Campbell (1867) and Dittenberger (1881) counted eight lexical features; Billig (1920) used fourteen metric features; while Ledger, in his book Re-Counting Plato (1989), used 37 lexical features. Given the problems of encoding and counting Greek words in the 1980s, Ledger defined a feature based on the first and last letters of a word, arguing that this would be the best way to observe lexical features of an inflected language, when limited by processing and memory power.
Empowered by technological progress, however, the last decade of NLP research has developed promising automated analytical methods to process and classify huge amounts of texts. For instance, the R-Package stylo makes it easy to extract lexical features, such as the frequency of words or the frequency of character n-grams; that is, the frequency of the sequence of n characters, where n is a set number (e.g. a 4-gram is the sequence of 4 characters). Both feature sets are complimentary to each other. While the frequency of words almost entirely focuses on function words (that is, words with little semantic meaning that still mark a stylistic decision by the author, such as καὶ, δὲ, μὲν, τε), measuring the sequence of 4 characters will also include, for instance, an author’s preference for certain compounds (e.g. περὶ, περίπλεω) or sound preference for certain combinations of consonants or vowels. In addition, leveraging the corpus of First1kGreek also enables a better understanding of platonic style. While it is difficult to compare platonic works just with themselves, it is possible to detect features with greater discriminatory power when we compare as many works as possible.
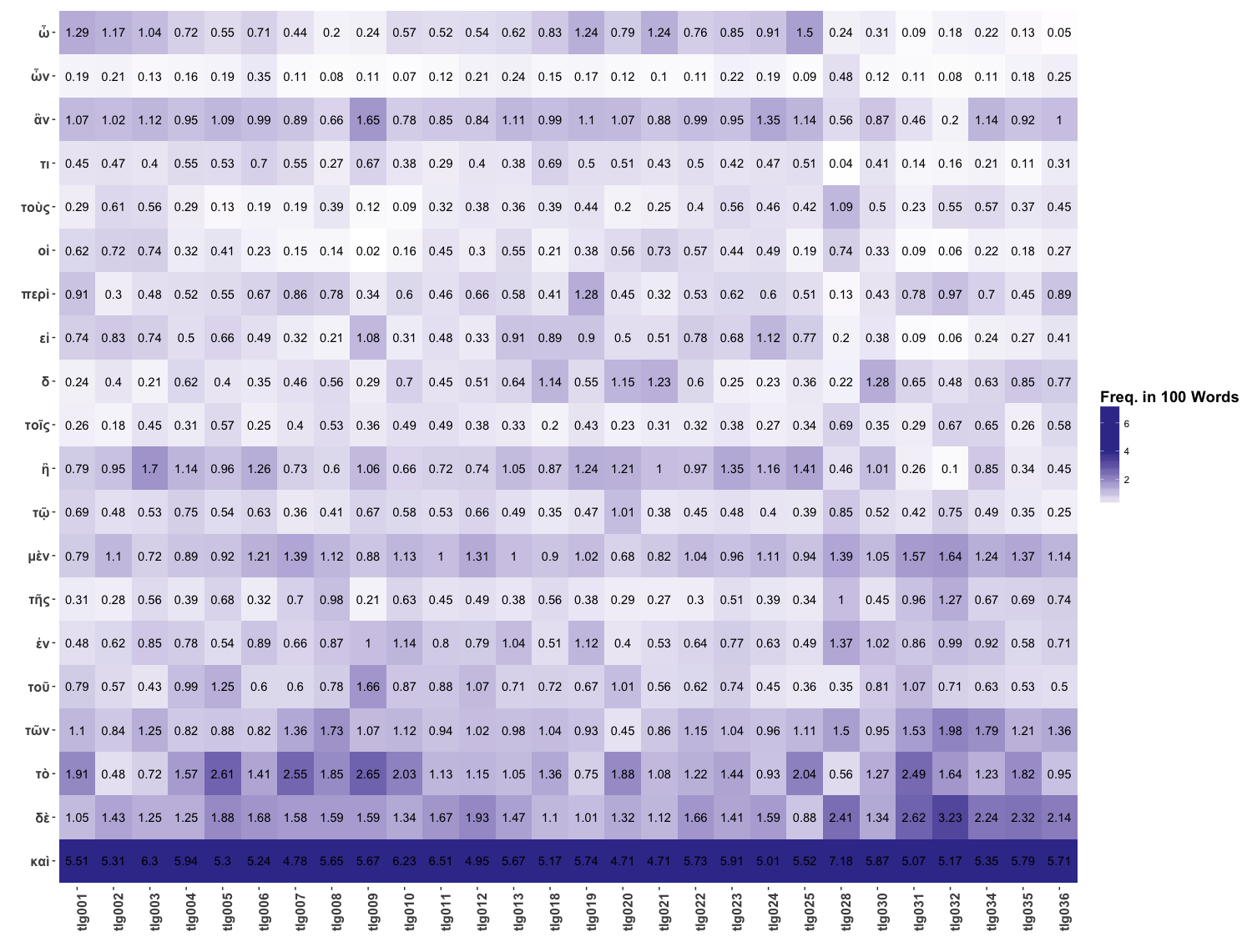
I ran a thorough series of stylometric experiments on the machine-actionable corpus of Greek text and focused on the finding that there is very little stylistic similarity between the Menexenus and the rest of the Corpus Platonicum (for a small excerpt of the data, see Figure 3). In addition, I could show that the traditional qualitative philological argument that Aristotle references the Menexenus is not convincing. In summary, the results indicate that the Menexenus wasn’t written by the authorial entity identified as Plato and I am currently preparing those results for a traditional print publication, having already presented them at the SCS in Boston, in a talk at the CHS Kosmos Society, and in a talk at the University of Cork.
Impact
The results of the stylometric analysis challenge our understanding of which works can be attributed to the authorial entity Plato, which in itself impacts our understanding of Greek literature and platonic philosophy. Moreover, the data created during the topic modeling and the stylometric analysis will help us to research other authors and to enable a multitude of scholarly inquiries. I will publish the data on Zenodo after the publication of the traditional print article, which I am currently preparing. Furthermore, the refinement of the tool Meletē ToPān and the development of the tool Metallō will enable scholars with few computational skills to perform similar analyses.
Figures and Tables
Select Bibliography
Blei, D. 2012. “Probabilistic Topic Models.” Communications of the ACM 55, no. 4:77–84.
Bradwood, L. 1992. “Stylometry and Chronology.” The Cambridge Companion to Plato, ed. Richard Kraut, 90–120. Cambridge.
Brett, M. R. 2012. “Topic Modeling: A Basic Introduction.” Journal of Digital Humanities 2, no. 1 available at http://journalofdigitalhumanities.org/2-1/topic-modeling-a-basic-introduction-by-megan-r-brett/
Dittenberger, W. 1881. “Sprachliche Kriterien fur die Chronologie der platonischen Dialoge.” Hermes 16:321–345.
Geßner, A. 2010. “Das automatische Auffinden der indirekten Überlieferung des Platonischen Timaios und die Bedeutung des Tools „Zitationsgraph“ für die Forschung.” Das Portal eAQUA – Neue Methoden in der geisteswissenschaftlichen Forschung I (Working Papers Contested Order No.1), ed. C. Schubert, and G. Heyer, 26–41. Leipzig.
Johnson, M., and H. Tarrant. 2014. “Fairytales and Make-Believe, or Spinning Stories about Poros and Penia in Plato’s Symposium: A Literary Study and Computational Analysis.” Phoenix 68, no. 3:291–312.
Ledger, G. R. 1989. Re-counting Plato. Oxford.
Posner, M. 2012. “Very Basic Strategies for Interpreting Results from the Topic Modeling Tool”, blog entry, available at: http://miriamposner.com/blog/very-basic-strategies-for-interpreting-results-from-the-topic modeling-tool/.
[1] GitHub is a data repository. You can download all Greek Perseus & First1KGreek works in XML format here https://github.com/PerseusDL/canonical-greekLit and here https://github.com/OpenGreekAndLatin/First1KGreek.