Citation with persistent identifier:
Kansa, Eric. “Contextualizing Digital Data as Scholarship in Eastern Mediterranean Archaeology.” CHS Research Bulletin 3, no. 2 (2015). http://nrs.harvard.edu/urn-3:hlnc.essay:KansaE.Contextualizing_Digital_Data_as_Scholarship.2015
https://www.youtube.com/watch?v=LxeQZg4a4Tw
Introduction
1§1 Archaeology is a highly regulated practice. Governments require permits for field work and often provide the majority of the funding for such work. Increasingly, national governments (and supranational entities, such as the European Union) recognize policy interests in the digital documentation that results from archaeological field work. Public policy toward archaeological research now sees the influence of the closely interrelated Open Government, Open Access and Open Data movements (Lake 2012; Kansa 2012; Beale & Beale 2012). Advocates for openness critique mainstream academic publishing as a form of commercial appropriation of publicly financed research (Lake 2012; Kansa 2012). They argue that the financing and oversight of research should create public goods in the form of data and publications free of access restrictions and intellectual property barriers.
1§2 The discourse surrounding Open Access and Open Data involves a mix of sometimes contradictory arguments and ideals (Kansa 2014). On the one hand, Open Access and Open Data advocacy sometimes appeals to reformist idealism and egalitarianism to democratize participation in research (see Kansa et al. 2013). Similarly, some Open Data advocates advance ethical arguments that digital data represents an important aspect of cultural heritage that needs preservation (Richards 1997). Such appeals to preservation play a particularly important role in archaeology, since so much of the archaeological record is under severe threat from economic and political forces and since much archaeological field documentation results from destructive research methods (excavation). On the other hand, some Open Access and Open Data advocacy, particularly among government officials, appeals to Neoliberalism, arguing that open scholarship speeds innovation, reduces costs, and empowers entrepreneurs who can “add value” to free and publicly available research and data (Kitchin 2014:61-62). Neoliberal advocacy for open research data tends to emphasize the economic gains and investment opportunities afforded by access to datasets in biomedical fields and other commercially important disciplines.
1§3 Neoliberal arguments for Open Data would have little appeal to humanists, including archaeologists, who work on questions of marginal commercial interest (Kansa 2014). While Open Access and Open Data critiques of conventional scholarly communications have gained traction and started to play a role in public policy, reform efforts still face tremendous hurdles in the humanities. The emerging policy and research interest in accessible digital data often clashes with academic norms and traditions that emphasize evaluation, recognition, and rewards more or less exclusively through conventional publishing. The lack of recognition for digital contributions means many archaeologists see little point in investing thought, effort, and training in information management. Intense competition for jobs and funding make deviation from established professional norms very risky, if not foolhardy. Similarly, the lack of financial resources that makes secure academic employment increasingly scarce means that few archaeologists and other humanists have the means to support collaboration with information technology specialists. As a result, archaeological data practices tend to be informal, sometimes even haphazard, and rarely the focus of much intellectual investment.
1§4 Current U.S. National Endowment for the Humanities (NEH) and National Science Foundation (NSF) data management policies illustrate some of the tensions inherent in incorporating data into scholarly institutions. Most discussions of data management use the language of bureaucratic compliance rather than intellectual engagement. These discussions assume data mainly need to be “archived” with institutional or disciplinary repositories (Kansa et al 2014). In other words, a researcher’s primary responsibility toward data currently centers on preservation. This emphasis on data preservation with institutional repositories represents a new normative best practice. In this perspective, conventional monographs or refereed journal papers remain the primary vehicle of research communications, and data are merely byproducts, not goals of scholarship.
1§5 The lack of rewards and the under-investment in digital data imposes large financial and intellectual costs on the discipline. Archaeological field work is labor intensive and requires expensive training (in a broad array of specializations) and facilities (laboratories, storage, conservation). Cost-cutting and financial austerity in public institutions and the academy make it increasingly difficult to sustain archaeological field work. These financial problems compound the devastating impacts of economically and politically motivated site destruction, neglect, and looting. All of these factors multiply the long-term significance of digital documentation. As much of the archaeological record is now digital, and as new archaeological data becomes increasingly difficult to acquire, the discipline needs to find ways to better preserve, understand, and use digital documentation. If archaeology continues to regard digital documentation as an after-thought, future generations will inherit a greatly diminished and fragmented record of the past.
Metcalfe’s Law and Digital Data in Classics
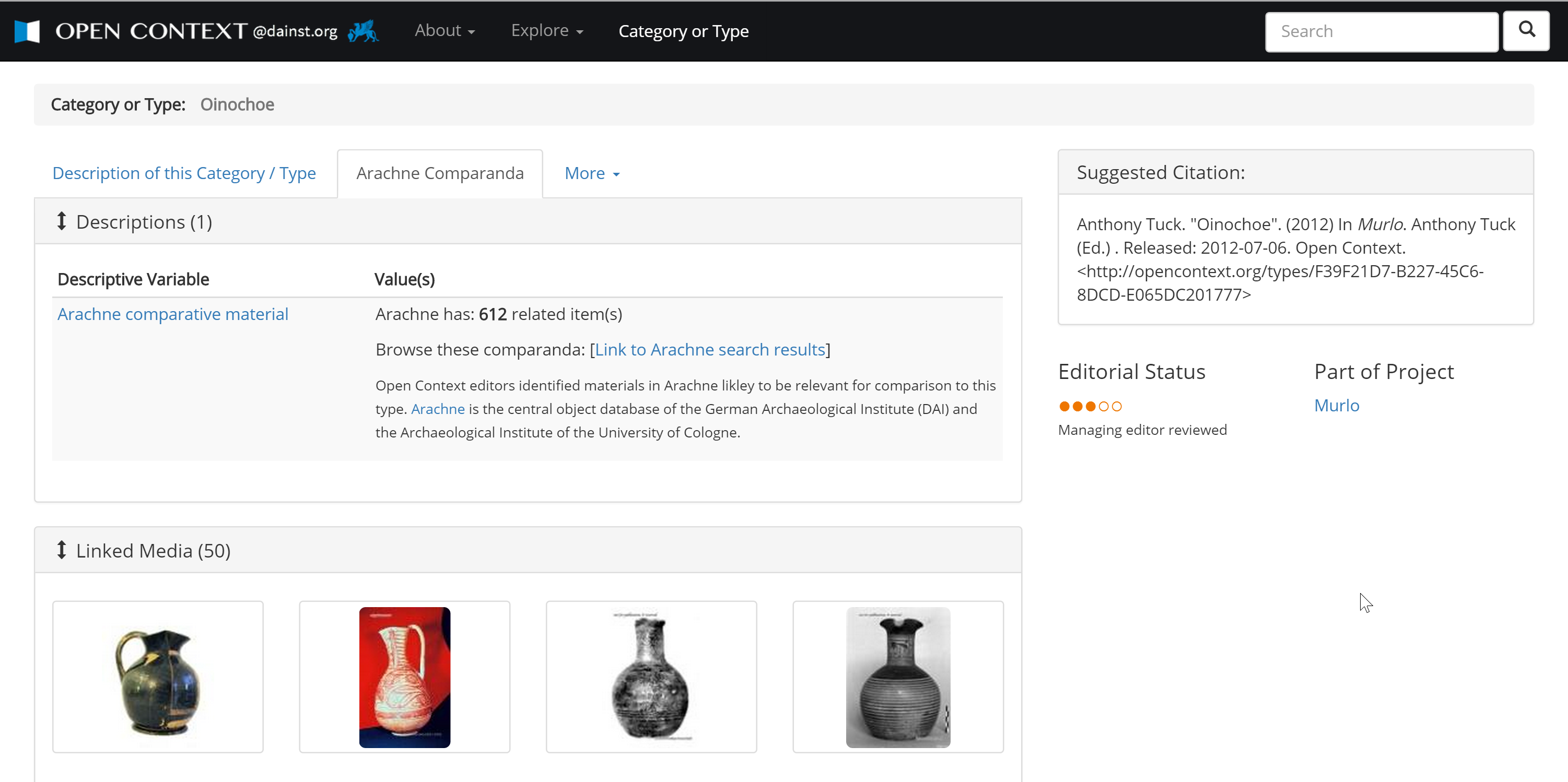
2§1 Archaeology faces tremendous and urgent challenges in the creation, use, and preservation of digital data. The field needs experimentation and intellectual investment in digital data to better situate data in archaeological method and theory. Classics and Classical archaeology provide fertile grounds for such experimentation. Classics already has very rich and diverse corpora of digital scholarly contributions. The pioneering efforts of the Perseus Digital Library[1], Pleiades[2], Arachne[3], FASTI online[4], and the Portable Antiquities Scheme[5], as well as increasing openness of museums in sharing collections data and metadata (especially the British Museum) creates many research opportunities for digitally enabled scholarship. The scale and diversity of digital resources in Classics is difficult to match in other areas of ancient studies.
2§2 In the 1980’s a telecommunications engineer named Bob Metcalfe (see Shapiro and Varian 1999:184) noted how the value of network connectivity grew with the square of the number of users. Simply put, if you were the sole owner of a telephone, this network device would be useless since you would have nobody to call. However, as more people connect to the telephone network, each telephone becomes more and more useful. This observation also can also apply to research data on the Web (Hendler & Goldbeck 2008). The data sharing paradigm of “Linked Open Data” explicitly centers on networking data by cross-referencing Web identifiers (URIs) for concepts and other entities of interests (such as records of archaeological sites, coins, pottery-types, sculpture, etc.).
2§3 Classics already boasts a rich network of linked data, adding Classical archaeological data to this network can yield more immediate research value, as will be described below. But before exploring Linked Open Data applications in classics, I should first introduce the approach in more detail. Linked Open Data consists of very simple atomic assertions, called “triples”:
| Abstract Model | Subject → | Predicate →(descriptive property / relation) | Object |
| Specific Example | Coin DT 5019 →http://opencontext.dainst.org/subjects/766ED8AA-3147-4CA2-6ECA-BD96BE0433BE | Has Mint →http://nomisma.org/ontology#hasMint | Antiochhttp://pleiades.stoa.org/places/658381 |
Table 1: Linked Open Data Triples
2§4 In general, a Web-URI identifies each part of a triple assertion (subjects, predicates, and objects). Because URIs are universally unique identifiers, one can construct triple assertions with URIs defined anywhere on the Web. In fact, that practice is encouraged, since it cross-references data across different Web collections. Because all triples have the same structure, one can aggregate data from multiple Linked Open Data sources. Indeed, the Pelagios Project[6] already demonstrates powerful information discovery and visualization applications from aggregating Linked Open Data describing several hundred thousand geographic assertions that mainly relate to Classical antiquity (Isaksen et al 2014).
2§5 There are many complications including trust, conceptual, semantic, and pragmatic issues that make Linked Open Data much less of a magic “silver bullet” in practice. However, in achieving significant positive “network effects”, Pelagios highlights important pragmatic strategies for successfully implementing Linked Open Data in practice. The links aggregated by Pelagios have very simple data modeling and semantics. Rather than worrying too much about how different “subjects” and “objects” relate to one another, Pelagios mainly notes that certain subjects (museum objects, coins, parts of historical documents) refer to common objects in gazetteers (ancient cities, provinces, kingdoms and the like). In contrast, other approaches toward Linked Data interoperability have focused more on semantic harmonization of the models (especially the “predicates”) used to relate data together. Linked Open Data approaches that center on the CIDOC-CRM[7], an important Cultural Heritage ontology, generally attempt integration by harmonizing to that common semantic model (see example Tudhope et al. 2011). Achieving consensus on common semantic models and implementing these models consistently is a steep challenge that needs more theoretical discussion and debate. Because of these theoretical and practical issues, the Linked Open Data implementations discussed below generally align more closely with Pelagios’s approach than CIDOC-CRM inspired approaches.
Organizing Intellectual Labor in Digital Classical Archaeology
3§1 The discussion about Pelagios and the CIDOC-CRM above hints at how data involves a host of conceptual and theoretical issues. Exploring these issues represents an important frontier of research, but an area poorly supported by current academic structures. Contextualizing data requires intellectual effort, expertise in data modeling, and an understanding of desired goals and outcomes that would result from integrating data. These activities require both information expertise and archaeological domain expertise (Kansa and Kansa 2013; Kansa et al 2014). Conventional institutional structures in the academy do a very poor job of supporting this novel combination of research interests, especially since preparing and integrating archaeological datasets can require a great deal of dedicated time and effort. Thus, the general lack of institutional support compounds the conceptual and theoretical challenges inherent in “digital archaeology”.
3§2 Because conventional academic departments generally do not support dedicated and sustained work with digital data in archaeology, much of the research conducted in this field is done by so-called “AltAcs” (alternative academics)—researchers without faculty appointments, who work inside and outside of universities (Nowviskie 2011). AltAc status is particularly common in the digital humanities, and indeed the term was first coined by Jason Hordy, a National Endowment for the Humanities program officer, based on his observations of the people involved in digital humanities projects. While AltAcs tend to be supported by “soft-money” sources and lack the job security of their tenure-track colleagues (another instance of pervasive Neoliberalism in the academy), they often do have more freedom to engage with technology, digital data, and work on cross-disciplinary projects.
An Open Context for Classical Archaeology
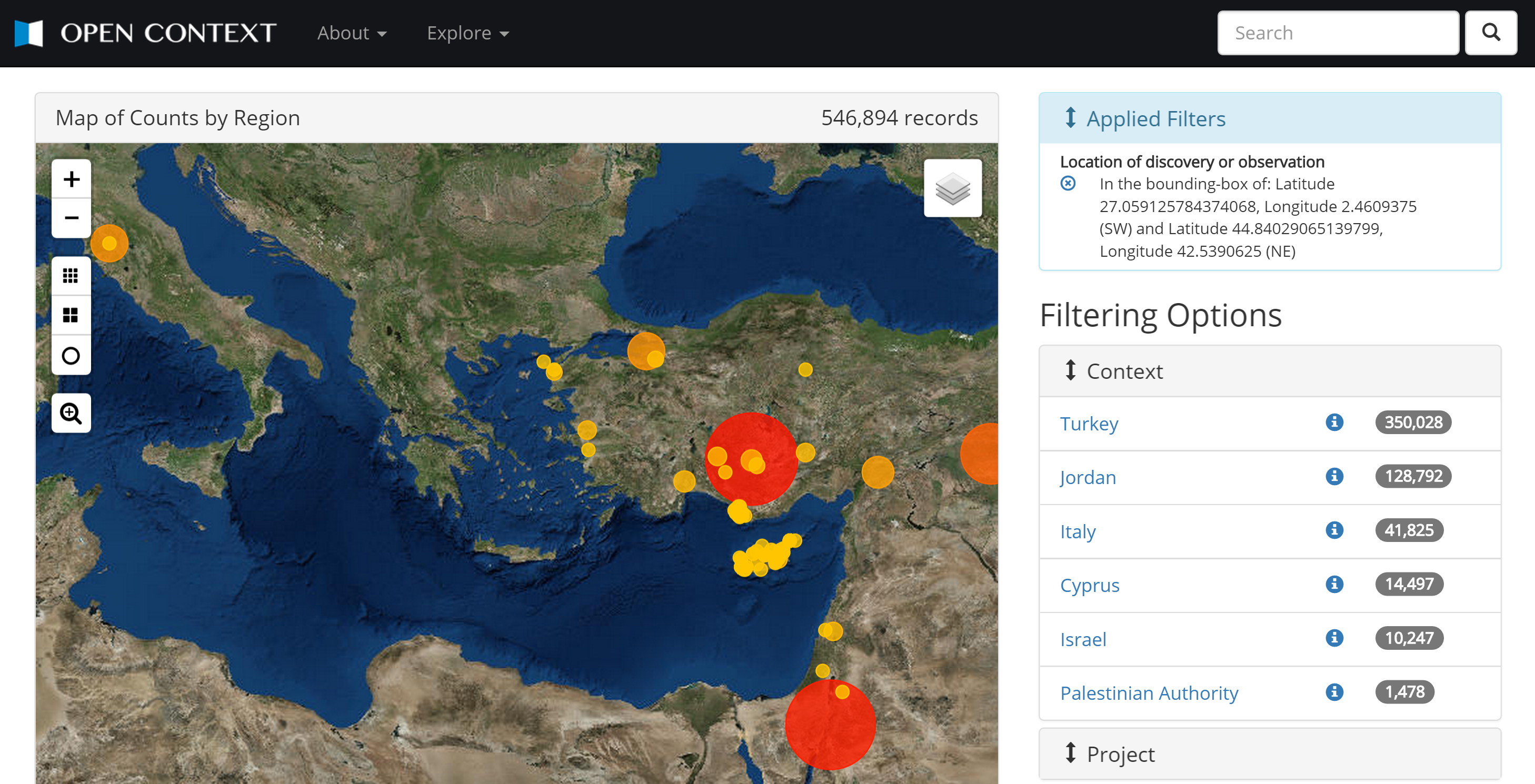
4§1 This discussion of AltAcs provides important background for Open Context, the data dissemination system used for the examples of networked data in Classical Archaeology described below. Open Context is now entering its eighth year of continual operation and iterative development. In 2015, public testing began on the latest version of Open Context, generously hosted on the German Archaeological Institute (DAI)’s cloud computing infrastructure (http://opencontext.dainst.org).
4§2 Open Context now publishes[8] more than a 1.2 million archaeological records from projects worldwide, a scale comparable to that of a major museum (for instance, the online collection of the Metropolitan Museum of New York makes some 407,000 records available). Open Context has made this remarkable achievement with much more limited budgets(should this be singular?) than the online collections of major museums. In addition, because of its diverse content, Open Context faces more complex informatics challenges than most museums. Open Context publishes a wide variety of archaeological data, ranging from archaeological survey data to excavation documentation, artifact analyses, chemical analyses of artifacts, and detailed descriptions of bones and other biological remains found in archaeological contexts. The range, scale, and diversity of these data require expertise in data modeling and a commitment to continual development and iterative problem solving.
4§3 A key aspect of Open Context’s approach to technology centers on interoperability, the capacity of an information system to efficiently exchange data with other information systems. As discussed above, the Web now boasts a tremendous wealth of data and talent invested by institutions world-wide, especially in Classics. To promote collaboration with these distributed efforts, Open Context focuses technical developments in two key areas:
- Application Program Interfaces (APIs): APIs enable people with some technical skills to combine information easily from different online sources to use in novel user interfaces, visualization and analysis[9]. They offer flexibility and customization so that data are not trapped in one website (see Kansa 2011). APIs also allow us to combine different information systems together in a Lego-like manner. For example, Open Context uses APIs to archive data with the University of California’s California Digital Library (CDL), thus facilitating long-term digital preservation.
- Linked Open Data: As discussed above, Linked Open Data represents current best practice to communicate the meaning of data on the Web. While APIs enable information to flow across systems, LOD uses links to further define data. For example, Open Context links to an online gazetteer to note that a certain coin was minted in the ancient city of Rome and not the modern town of Rome, Georgia[10]. Open Context uses linked data primarily for vocabulary control in order to relate idiosyncratic, project-specific terminologies with concepts used by wider communities.
4§4 Open Context adapts a “publishing” metaphor for data sharing to help set expectations about the labor and intellectual investments needed for meaningful data dissemination (Kansa and Kansa 2013). The phrase “data sharing as publication” helps to convey the idea that data dissemination involves co-production, where data “authors” and specialized “editors” work collaboratively and contribute different elements of expertise and take on different professional responsibilities. A publishing metaphor is also widely understood by the research community, helping to convey the idea that data publishing implies efforts and outcomes similar to conventional publishing. We also hope that offering a more formalized approach to data sharing can promote professional recognition, helping to create the reward structures that make data reuse less costly and more rewarding, both in terms of career benefits and opening new research opportunities in reusing shared data.
4§5 Experiments in “data publishing” in multiple disciplines (see Kratz and Strasser 2014) attempt to address some of the incentive problems with research data management. The journals Internet Archaeology and the Journal of Open Archaeological Data similarly try to encourage professional recognition for data sharing through publication of peer-review “data papers” (introductory summaries about datasets in repositories). However, Open Context’s approach is somewhat different, in that Open Context’s editorial and publication workflows focus more effort on preparing and structuring data for Web dissemination (see below). In contrast, Internet Archaeology or the Journal of Open Archaeological Data, mainly focus on reviewing datasets stored as files in digital repositories. In fact, Open Context’s data publication workflows, which reformat and restructure data for Web dissemination and API and Linked Open Data interoperability, stand in marked contrast to the approaches taken by most digital repositories. Open Context’s approach is more expensive and harder to “scale” than conventional digital repositories, since it requires more expert human labor to prepare data. But optimizing for cost and scale should not eclipse the need to successfully communicate meaningful data. Grant data management plans will achieve little if they only fill our digital repositories with messy and incomprehensible spreadsheets.
4§6 Archaeology needs a mixture of approaches and experimentation to find good solutions to the challenge of making data a recognized and valued professional contribution. While calling for experimentation, I do not mean to imply that one way of organizing data is as good any other. Our past research in data integration and reuse in zooarchaeology highlights the need for greater scrutiny and professionalism in data modeling (Kansa et al 2014). Some ways of organizing and structuring data limit future interpretative possibilities and can make reuse harder. These issues again highlight how method and theory in data and data modeling need greater professional engagement.
Method, Theory, and Practice in Linking Archaeological Data
5§1 Having discussed some of the professional and institutional issues involved in working with research data, we must return to a more central issue: what can we learn about the past by investing effort in digital archaeological data (Huggett 2015a,b)? After all, Open Context’s more labor intensive approach to publishing data can only be justified if it leads to greater understanding of archaeological questions.
5§2 We can begin to explore this topic by looking more closely at Open Context’s publication process. After extracting archaeological information from source data files submitted by data contributors, Open Context’s editors use Open Refine[11] (formerly Google Refine) to perform validation checks, clean up tabular data, and link certain concepts within datasets to shared vocabularies (more below). Open Context then imports cleaned and annotated data from Open Refine and editors map the imported data to Open Context’s own data structures.
5§3 This process retains the original identifiers, descriptive properties, terminologies and vocabularies submitted by data contributors. The process also makes implicit relationships within source datasets more explicit. For example, certain columns (fields) in a source data table may have values that describe the ceramic type of a sherd identified by a database key in another field. Publishing in Open Context makes this descriptive relationship explicit. Similarly, the sherd (identified by a database key) may come from an archaeological context or deposit identified by keys in another field. Publishing in Open Context also makes those containment and context relationships explicit.
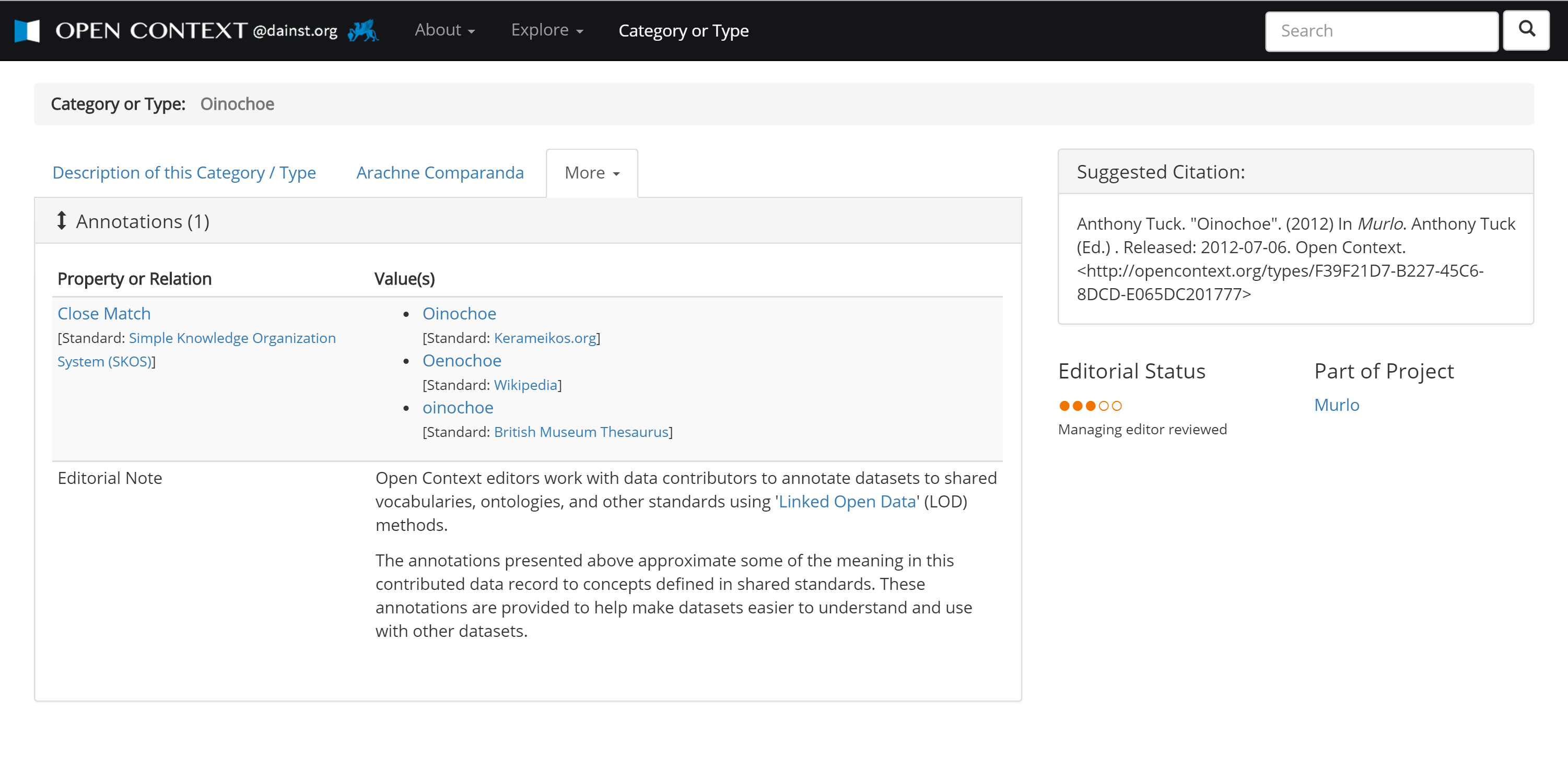
5§4 In order to more explicitly define these relationships while still accommodating the wide diversity of recording systems, terminologies, and typologies that archaeologists use requires Open Context to organize and represent data at a high level of contextual abstraction. I am currently drafting a formal description of these abstractions as an ontology (in the computer science sense of the word) using an open standard called OWL (Web Ontology Language). This ontology describes the abstract data structures used to organize data published by Open Context. In addition, the new version of Open Context explicitly models the vocabularies, typologies, and terminologies created by contributing researchers using SKOS (Simple Knowledge Organization Systems), a popular linked data standard for representing controlled vocabularies.
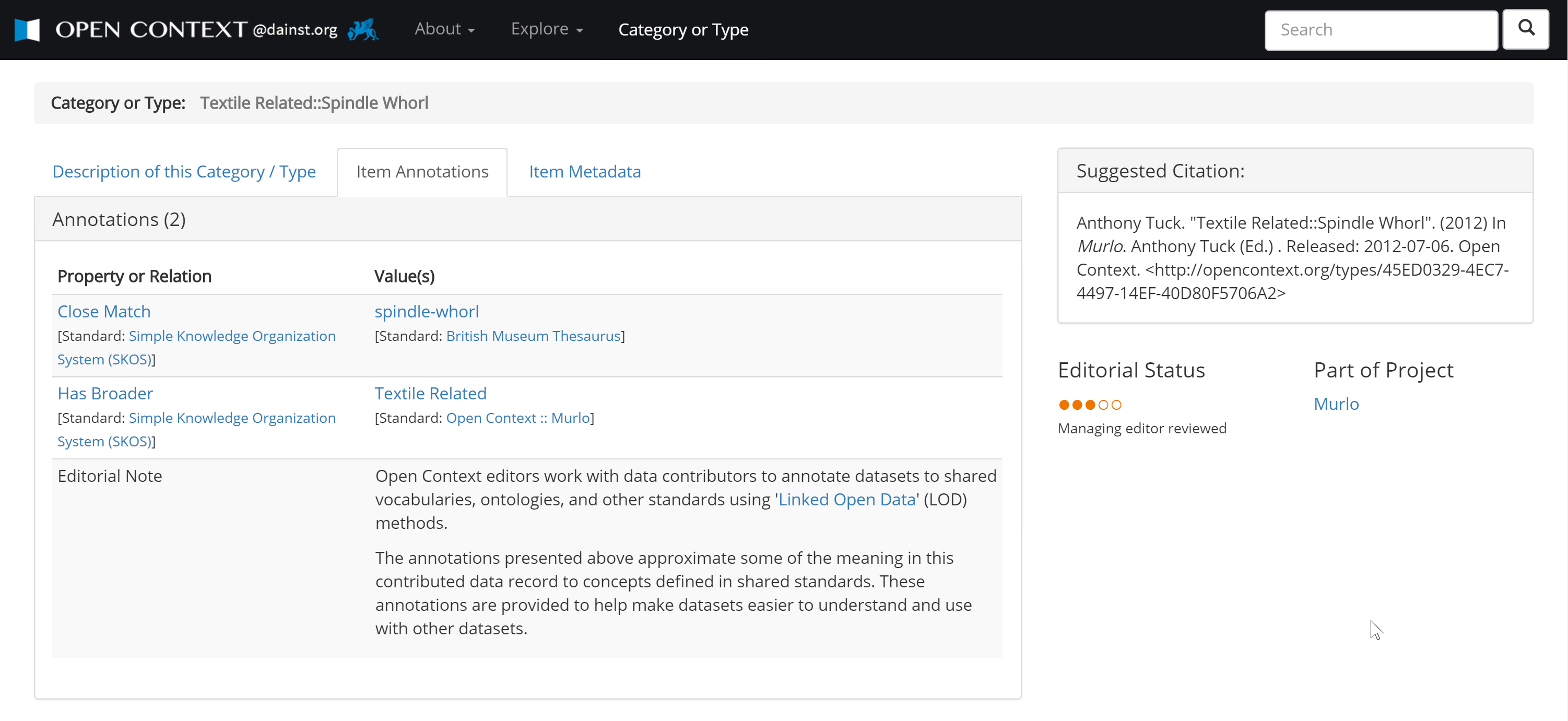
5§5 The goals and results of important data differ greatly from the way conventional repositories work. Conventional digital repositories mainly strive to preserve digital files and make them discoverable with some metadata documentation. The main object of search and citation in most digital repositories centers on digital files (spreadsheets, image files, relational databases, etc.). In contrast, Open Context differs from digital repositories in how it organizes information for dissemination. By importing data into its generalized and abstracted data structures, Open Context can make the archaeologically meaningful “entities” (records of sites, potsherds, bones, sculpture fragments, coins, etc.) the main objects of search and citation.
5§6 Though more labor intensive, Open Context’s approach enables much more granular access and citation of specific and archaeologically meaningful items of interest. This approach helps make the complexity and scale of archaeological data more manageable. For example, an ancient coin may be represented in several different data tables and files in the documentation of an archaeological project. Information about a given coin can exist in a finds catalog, a context inventory, a specialist numismatic spreadsheet, a photo log, several digital images, and a table of XRF results. Thus, information about the coin could be scattered among tens of thousands of other records, in multiple tables, and in multiple files, all organized with different schema. This point highlights the limitations of repository archiving. Data archiving makes the “file” the main object of discovery and citation, and files can be very arbitrary and opaque containers for items of archaeological interest (such as coins). Thus, if we limit data curation practices to “archiving” digital files, citation of specific archaeologically meaningful entities (like a coin) becomes nearly impossible.
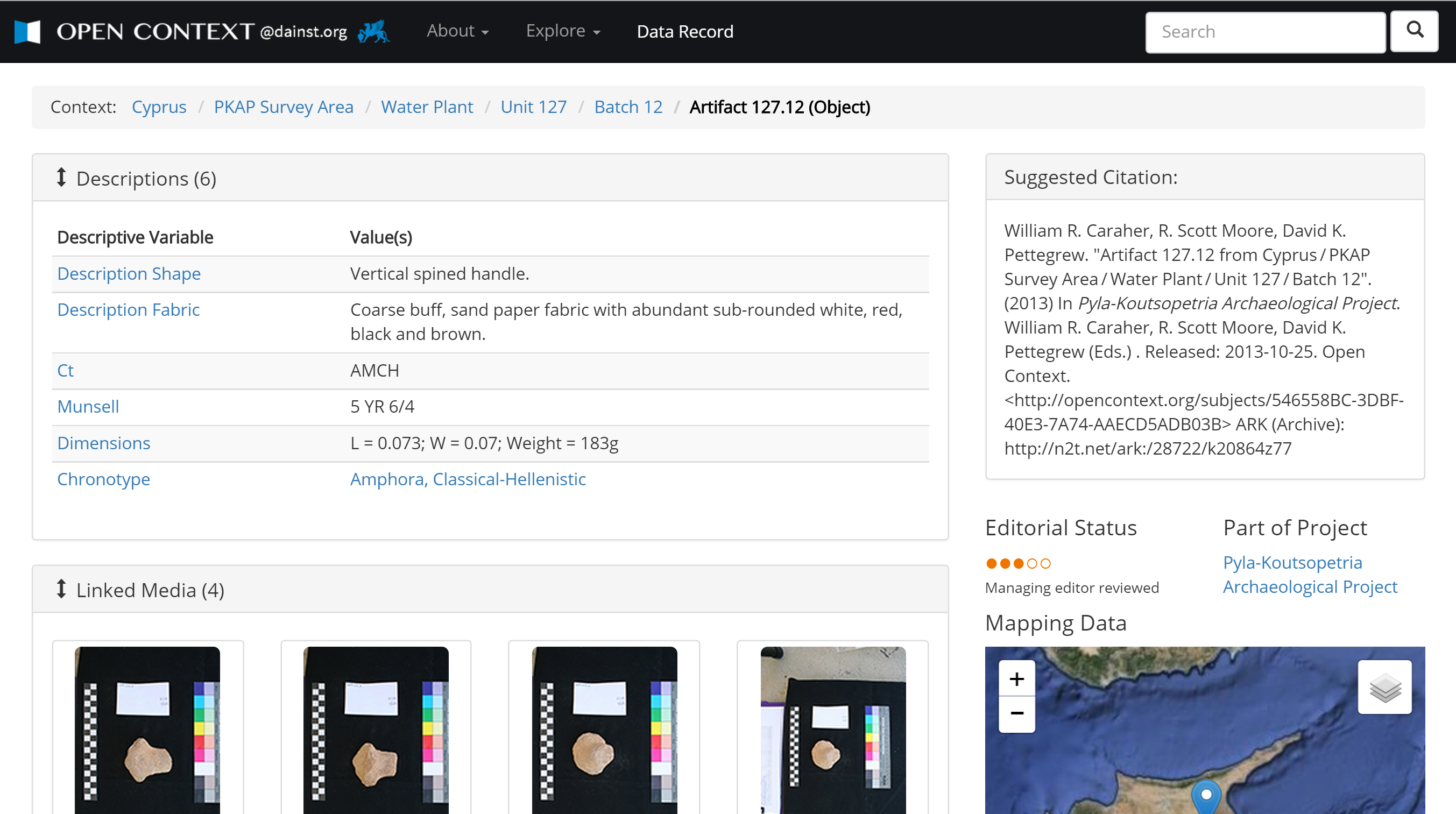
5§7 The issue of referring to specific archaeological items goes beyond convenience. It plays an important role in interoperability. Linked Open Data, the current best practice for data sharing and interoperability, centers on relating data across the Web by referring to stable Web URIs (a URI is a URL that is also a globally unique identifier). Because Open Context mints stable Web URIs for each item of archaeological interest (as defined by the contributing researcher), Open Context makes it possible to use Linked Open Data with much more granular and specific information than feasible with a typical repository, where one can only link to a large aggregate of information encoded in a file. Open Context makes it possible for anyone to refer to precisely specified sites, coins, potsherds, or even individual categories in a typology, and link those items with items published anywhere else on the Web. This last point highlights a key advantage of greater granularity in Linked Open Data applications.
5§8 Open Context is not the only system publishing archaeological data with such granularity. ArkDB[12], Heurist[13], FAIMS[14], the Çatalhöyük Living Archive[15], and other specialized systems, especially various systems hosted by the American Numismatic Society[16], and the Kenchreai Archaeological Archive (see below) similarly offer high granularity access to data. These systems all have different organizational schemas and approaches to data modeling. Such information diversity should be seen as a feature, rather than a bug. As a discipline, archaeology should encourage such diversity and experimentation because the theoretical and methodological challenges inherent in making sense of data are as rich as any other research program. The need to respect and encourage continued thought, experimentation, and intellectual freedom in creating and using archaeological data underlies choices in Open Context’s design. As described above, Open Context maintains the descriptive terminologies and vocabularies researchers define (usually informally) for their digital documentation. In many cases, archaeologists customize their recording systems and adapt them to different research settings. One’s research designs, theoretical perspectives, and interpretive priorities in large measure determine how one organizes and classifies the archaeological record (Schloen, 2001; Kansa and Kansa 2011; Kintigh, 2006).
5§9 We will achieve little if we sacrifice interpretive freedom and innovation in methods and research design at the altar of (apparent) data interoperability. If we wanted to maximize the production of lower cost, easily interoperable data, we could impose predetermined “standards” on archaeological data creation. It would certainly be an easier and cheaper approach than Open Context’s labor-intensive methods to model and index diverse data abstractly. However, such attempts at standardization would (justifiably) face great resistance, since standardization would limit researchers’ autonomy in how they conduct field work. Archaeology is sometimes described as an artisanal craft (Shanks and McGuire 1996), and many archaeologists would understandably reject attempts to “mass-produce” standardized and highly fungible data.
Toward Linked Data in Classical Archaeology
6§1 Archaeological data will attract greater intellectual commitment and institutional support if we can point to compelling and tangible examples of archaeological research outcomes drawn from aggregating heterogeneous archaeological data. Between the fall of 2014 and the spring of 2015, Open Context underwent a complete software rebuild. The changes, including shifting programming languages from PHP to Python and integrating Postgres as a backend database, were aimed at better supporting the publication of Linked Open Data. Past successes in using data publishing and Linked Open Data annotation to encourage data reuse and syntheses in zooarchaeology (see Kansa et al 2014; Arbuckle et al 2014) motivated these technical investments. The revised version of Open Context makes “machine-readable” (easy to parse by software) data more easily available with updated and redesigned APIs. This facilitates interoperability by enabling users and their software agents to access data in formats that can be easily loaded into other databases and combined with other data, or can be easily manipulated by software for analysis and visualization.
6§2 The upgrade of Open Context enables more theoretically justifiable ways of organizing archaeological data. One of the most important aspects of this upgrade centers on modeling archaeological time periods. Chronological periods are key organizing principles in archaeology (Rabinowitz 2014). While important, archaeologists mainly define periods informally, and the lack of precision makes it difficult to computationally relate periodized archaeological data together. Prior attempts to systematize periods have had a number of limitations. For instance the Library of Congress Subjects Headings and the Getty Art and Architecture Thesaurus have defined a few general time periods but do not model the geographic coverage of their named periods. Archaeological periods have spatial as well as temporal coverage. The “Archaic” period means something very different to Classical archaeologists than it does to North American archaeologists. More recent attempts at systematizing periods, such as ARENA[17], define a geographic scope, usually a contemporary national boundary, for each periodization.
6§3 However, aligning periodization schemes with scholarly needs is not simply a matter of accounting for time and space. Researches sometimes define periods and refer to periods to advance certain interpretive arguments. The past two decades have witnessed ongoing controversies over synchronizing Late Bronze Age and Iron Age periods across regions in the Eastern Mediterranean (particularly the Aegean and the Southern Levant) (to cite a few: Manning et al 2001; Coldstream and Mazar 2003; Finkelstein and Piasetzky 2003; Sharon et al 2007; Plicht et al 2009; Fatalkin et al 2011). For instance, the so-called “High”, “Middle”, and “Low” chronologies have important implications in understanding a variety of historical and social changes including the end of the Mycenean palatial system, emergence of the “Sea Peoples”, and political developments in Biblical Israel (recently reviewed by Joffe 2007 and Boaretto 2015). Simply defining a standard chronology, even if scoped to a given geographic region, therefore could pave over and obscure important interpretative issues and debates.
6§4 Again, this issue highlights how data standards cannot be divorced from more general issues in archaeological method, theory and interpretation. The PeriodO project (http://perio.do), led by Adam Rabinowitz (a classical archaeologist), Ryan Shaw (an information scientist) and myself, attempts to systematize periods in a more theoretically defensible manner (Shaw et al, in press). In addition to modeling the geographic and temporal scope of a period, PeriodO also includes information about the authority that defined the period. Because each PeriodO period has a computationally explicit definition, datasets annotated with these periods can be aggregated and compared. Furthermore, because PeriodO documents the authority that defined a given period, it helps provide some clues about interpretive perspectives. For example, it enables one to use a High, Middle, or a Low Chronology version of the period “Iron Age I”. Since preference for a High or Low chronology marks a preference for a theoretical camp, PeriodO helps to document an important element of scholarly context.

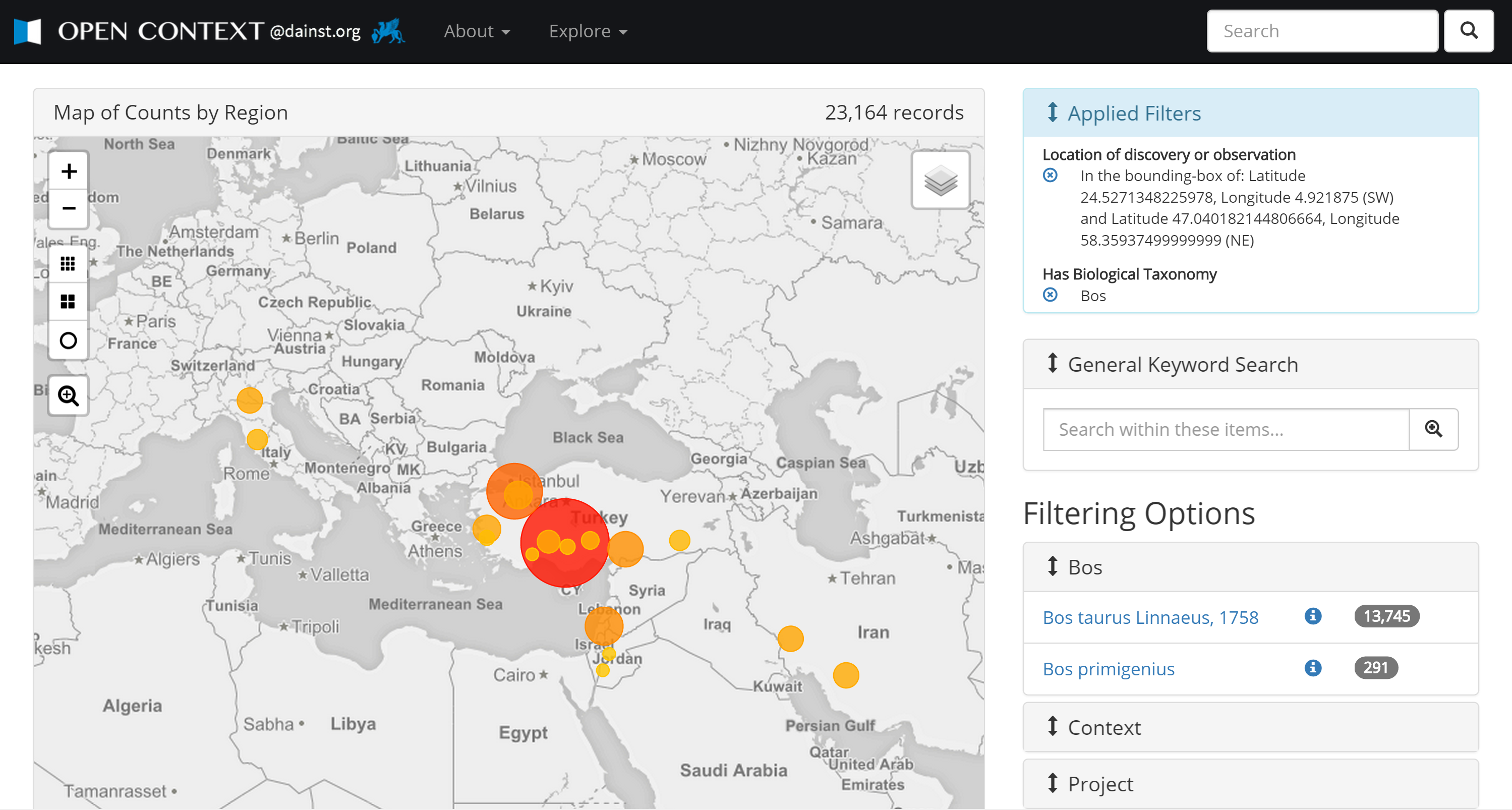
6§5 Open Context’s use of PeriodO identifiers will relate Open Context data publications with many other corpora. Ariadne, a major European Union funded archaeological data aggregation project has also adopted PeriodO. This means we will start seeing “network effects” (as in the above discussion of Metcalfe) with regard to historical periodization. In addition, Open Context will adopt PeriodO’s approach of including scholarly authority to the modeling of other types of concepts. Periods are just one case where defining and modeling concepts used to organize data reflect and operationalize interpretive choices and research agendas. For example, Open Context is now publishing the Pyla-Koutsopetria Archaeological Project (PKAP) a dataset documenting an archaeological survey near Larnaka, Cyprus, led by William Caraher. In this project, Caraher and his colleagues defined the “chronotype” system for classifying very fragmentary surface finds gathered in the survey (Caraher et al 2007; Tartaron et al 2006). Because body sherds (especially of undecorated utilitarian wares) make up the majority of the finds collected in the survey, Caraher’s team needed an alternative to ceramic typologies based on vessel forms and decorations. The chronotype system helps organize survey pottery to explore questions about diachronic patterns in settlement in the survey area. Again, this organizational scheme reflects the close relationship between research methods and classification.

6§6 Current development work on Open Context aims to make publication of classification systems like chronotype more formal and explicit. In the spring of 2015, I worked with Caraher to update the PKAP dataset in Open Context to formally model concept hierarchies in the chronotype system using SKOS. Formal modeling of the PKAP chronotype system will help enable comparisons with the Eastern Korinthia Archaeological Survey. This project, which is now in preparation for publication with Open Context, also used a variant of the chronotype system to organize materials collected in survey near Kenchreai, to the east of Corinth (Tartaron et al 2006). Explicit cross-referencing between the PKAP chronotype system and the Eastern Korinthia Archaeological Survey chronotype system will enable researchers to compare directly the distributions of material culture collected in two different surveys.
6§7 Formal description and modeling of the chronotype system will also promote wider interoperability with other datasets published by Open Context and other venues. For example, a multi-institutional collaboration led by Joseph Rife (Vanderbilt University) and Sebastian Heath (New York University) has started to digitize and publish American excavations at Kenchreai (the Kenchreai Archaeological Archive; http://kenchreai.org/kaa/). This field work did not use the chronotype system, so its materials are not immediately comparable to the Eastern Korinthia Archaeological Survey. However, since this survey dataset directly complements data from the excavations at Kenchreai, we need to explore ways to cross-reference relevant concepts between these projects.
6§8 Fortunately, Linked Open Data approaches can help establish such correspondences. Sebastian Heath, a pioneer in Linked Data for archaeology (see Heath 2010), has already put some of the Kenchreai data on the Web and has minted stable Web URIs for individual archaeological observations and categories of material culture, including ceramic types. Some of the ceramic types defined by the Kenchreai Archaeological Archive can be related to certain classes defined by the chronotype system. We can assert relationships directly between chronotypes published by Open Context and relevant types published by the Kenchreai Archaeological Archive.
6§9 We can also assert such relationships less directly, especially if both the Kenchreai Archaeological Archive and Open Context relate relevant types to typologies curated by other systems. Fortunately, some relevant material culture typologies, especially in ceramics, have started to move online. For example, Kerameikos.org (http://kerameikos.org/) offers URIs for important pottery types in Classical archaeology. In addition, the Levantine Ceramics Project (http://www.levantineceramics.org/) hosts a collaboration of ceramic experts working in the Eastern Mediterranean that curates information about ceramic types, wares, and fabrics. These expertly defined and curated types can be used for Linked Open Data applications. As more and more data go online, agreement on common vocabularies becomes important. By linking to a single common point of reference, we avoid the need to link each individual dataset in Open Context with every relevant dataset that may appear on the Web. Efficient scaling is needed, because in addition to the PKAP survey and the Eastern Korinthia Archaeological Survey, Open Context is also publishing excavation results from Polis Chrysochous (ancient Arsinoe) in Cyprus, and also the very large Bay of Iskenderun Landscape Archaeology and Survey project (Gunnar Lehman and Ann Killebrew). Thus, by pointing to common nodes with useful shared vocabularies, Open Context and other sites (like the Kenchrai Archaeological Archive) can integrate multiple datasets more efficiently.

Conclusions
7§1 A careful reader may think that the above discussion about cross-referencing with a centralized hub like the Levantine Ceramics Project directly contradicts the earlier discussion about how archaeological informatics needs to respect and encourage diversity in classification and information organization. Indeed, if we required every archaeologist to simply use ceramic types defined by the Levantine Ceramics Project, we would be guilty of attempting to promote arbitrary and sometimes inappropriate standardization.
7§2 Therefore, it is important to highlight how cross-referencing data is not the same as standardizing data. Open Context publishes data described by researcher-defined classification systems. While some researcher-defined types will not be easily linked to the classes defined by other researchers, some can be cross-referenced. Linked Open Data helps make those cross-references and correspondences formally defined and explicit so they can be reused or critiqued by other researchers. Cross-referencing data in this way is a form of annotation. It adds additional linkages, context, and layers of meaning to data rather than attempting to standardize what data researchers should or should not create in the first place.
7§3 Thus, in my view, the key need for the discipline is not to standardize what archaeologists say or cannot say about the past. Rather, we should aim for data management practices that make modeling and classification, including definition of new classification schemes, more formal and explicit. If archaeologists want to meaningfully reuse and compare datasets from multiple field projects, and if they do not want to accept standardized recording practices, then they must accept greater responsibility in formally and precisely documenting and modeling their own “customized” approaches to organizing data. They must also explicitly relate their own systems of organization to the systems created by their colleagues. Thus, our efforts to encourage greater formalism and precision in archaeological data modeling do not call for “standardized” practice. Rather, we seek to put the craft of archaeology on a more intellectually rigorous foundation.
7§4 As discussed in this paper, the logical formalism and precision demanded by computational approaches does not reflect a naive positivism or empiricism. Data do not speak for themselves. Creating, aggregating, and using data involve a host of potentially contestable interpretive choices (Shott 2014; Dallas 2015). The strategies of data publishing and Linked Open Data annotation and cross-referencing discussed in this paper represent attempts to put the interpretation of data on a better theoretical foundation. Nevertheless, these strategies are still incomplete and many challenges remain. Building synthetic understanding from datasets created by different researchers, research agendas, sampling strategies and interpretive goals and methodological differences requires more than just Linked Open Data vocabulary alignment and cross-referencing (see Faniel et al 2014). We also need much better ways of evaluating what data can and cannot be compared with confidence (see Huggett 2015a). Though daunting, this challenge is not at all unique to digital archaeology. Archaeologists routinely, though tacitly, attempt to synthesize a bigger picture from the articles, books, and reports created by their colleagues. The use of digital data simply puts these interpretive decisions into sharper focus, thus making digital data in archaeology a tremendously fertile ground for further inquiry.
Acknowledgements
I owe tremendous thanks to the German Archaeological Institute (DAI) and the Harvard Center for Hellenic Studies (CHS) for sponsoring a fellowship that offered invaluable dedicated time needed to focus on the coding and data preparation discussed in this paper. In particular, I want to thank Prof. Dr. Reinhard Förtsch (DAI) for supporting the test development of Open Context on DAI computing infrastructure, Lanah Koelle, Cynthy Mellonas, and the rest of the CHS staff and fellows for such a welcoming and collegial fellowship experience. Finally, I want to express my deepest gratitude to Sarah Kansa, Open Context’s lead editor and my spouse, for her thoughtful comments and edits on drafts of this paper, and for her patience during my extended absence.
Bibliography
Arbuckle, B.S., et al. 2014. Data Sharing Reveals Complexity in the Westward Spread of Domestic Animals across Neolithic Turkey. PLoS ONE, 9(6):e99845. Available at: http://dx.doi.org/10.1371/journal.pone.0099845 [Accessed May 25, 2015].
Beale, N., and G. Beale, 2012. The potential of open models for public archaeology. Available at: http://eprints.soton.ac.uk/355830/ [Accessed May 25, 2015].
Boaretto, E. 2015. Radiocarbon and the Archaeological Record: An Integrative Approach for Building an Absolute Chronology for the Late Bronze and Iron Ages of Israel. Radiocarbon, 57(2):207–216. Available at: https://journals.uair.arizona.edu/index.php/radiocarbon/article/view/18554 [Accessed May 25, 2015].
Coldstream, N., and A. Mazar. 2003. Greek Pottery from Tel Reḥov and Iron Age Chronology. Israel Exploration Journal, 53(1):29–48. Available at: http://www.jstor.org/stable/27927022 [Accessed May 25, 2015].
Dallas, C. 2015. Jean-Claude Gardin on Archaeological Data, Representation and Knowledge: Implications for Digital Archaeology. Journal of Archaeological Method and Theory, 1–26. Available at: http://link.springer.com/article/10.1007/s10816-015-9241-3 [Accessed May 25, 2015].
Davis, J.L., and S.E. Alcock. 1998. Sandy Pylos: an archaeological history from Nestor to Navarino, Austin: University of Texas Press.
Fantalkin, A., I. Finkelstein, and E. Piasetzky. 2011. Iron Age Mediterranean Chronology: A Rejoinder. Radiocarbon, 53(1):179–198. Available at: https://journals.uair.arizona.edu/index.php/radiocarbon/article/view/3453 [Accessed May 25, 2015].
Finkelstein, I., and E. Piasetzky. 2003. Recent radiocarbon results and King Solomon. Antiquity, 77(298):771–779. Available at: http://journals.cambridge.org/article_S0003598X00061718 [Accessed May 25, 2015].
Hendler, J., and J. Golbeck. 2008. Metcalfe’s law, Web 2.0, and the Semantic Web. Web Semantics: Science, Services and Agents on the World Wide Web, 6(1):14–20. Available at: http://www.sciencedirect.com/science/article/pii/S1570826807000595 [Accessed May 22, 2015].
Housley, R.A., et al. 1999. Radiocarbon, Calibration, and the Chronology of the Late Minoan IB Phase. Journal of Archaeological Science, 26(2):159–171. Available at: http://www.sciencedirect.com/science/article/pii/S0305440398903120 [Accessed May 24, 2015].
Huggett, J. 2015a. A Manifesto for an Introspective Digital Archaeology. Open Archaeology, 1(1). Available at: http://www.degruyter.com/view/j/opar.2014.1.issue-1/opar-2015-0002/opar-2015-0002.xml [Accessed May 25, 2015].
Huggett, J. 2015b. Challenging Digital Archaeology. Open Archaeology, 1(1). Available at: http://www.degruyter.com/view/j/opar.2014.1.issue-1/opar-2015-0003/opar-2015-0003.xml [Accessed May 25, 2015].
Isaksen, L., et al. 2014. Pelagios and the Emerging Graph of Ancient World Data. In Proceedings of the 2014 ACM Conference on Web Science, 197–201. WebSci ’14. New York, NY, USA: ACM. Available at: http://doi.acm.org/10.1145/2615569.2615693 [Accessed May 25, 2015].
Kansa, E.C., S.W. Kansa, and B. Arbuckle. 2014. Publishing and Pushing: Mixing Models for Communicating Research Data in Archaeology. International Journal of Digital Curation, 9(1):57–70. Available at: http://www.ijdc.net/index.php/ijdc/article/view/9.1.57 [Accessed May 25, 2015].
Kansa, E. 2014. The Need to Humanize Open Science. In Issues in Open Research Data S. Moore, ed. Ubiquity Press. Available at: http://www.ubiquitypress.com/site/books/detail/12/issues-in-open-research-data/ [Accessed May 25, 2015].
Kansa, E. 2012. Openness and archaeology’s information ecosystem. World Archaeology, 44(4):498–520. Available at: http://escholarship.org/uc/item/4bt04063/ [Accessed January 30, 2013].
Kansa, E.C. 2010. Open Context in Context: Cyberinfrastructure and Distributed Approaches to Publish and Preserve Archaeological Data. The SAA Archaeological Record, 10(5):12–16. Available at: http://www.alexandriaarchive.org/blog/ [Accessed January 12, 2011].
Kansa, E.C., and S.W.Kansa. 2011. Toward a Do-It-Yourself Cyberinfrastructure: Open Data, Incentives, and Reducing Costs and Complexities of Data Sharing. In Archaeology 2.0, ed. E. C. Kansa, S. W. Kansa, and E. Watrall, 57–91. Cotsen Institute Press. Available at: http://escholarship.org/uc/item/1r6137tb [Accessed April 7, 2012].
Kansa, E.C., and S.W. Kansa. 2013. We All Know That a 14 Is a Sheep: Data Publication and Professionalism in Archaeological Communication. Journal of Eastern Mediterranean Archaeology and Heritage Studies, 1(1):88–97. Available at: http://muse.jhu.edu/login?auth=0&type=summary&url=/journals/journal_of_eastern_mediterranean_archaeology_and_heritage_studies/v001/1.1.kansa01.html [Accessed September 30, 2013].
Kansa, E.C., S.W. Kansa, and L. Goldstein. 2013. On Ethics, Sustainability, and Open Access in Archaeology. The SAA Archaeological Record, 13(4):15–22. Available at: http://www.saa.org/Portals/0/SAA/Publications/thesaaarchrec/September2013.pdf [Accessed April 16, 2014].
Kintigh, K. W. 2006. The Promise and Challenge of Archaeological Data Integration. American Antiquity, 71(3):567–578. Available at: http://www.anthrosource.net/doi/abs/10.1525/an.2005.46.7.16.2 [Accessed July 10, 2008].
Kitchin, R. 2014. The Data Revolution: Big Data, Open Data, Data Infrastructures and Their Consequences. SAGE.
Kratz, J., and C. Strasser. 2014. Data publication consensus and controversies. F1000Research, 3. Available at: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC4097345/ [Accessed May 25, 2015].
Lake, M. 2012. Open archaeology. World Archaeology, 44(4):471–478. Available at: http://www.tandfonline.com/doi/abs/10.1080/00438243.2012.748521 [Accessed April 28, 2013].
Manning, S.W., et al. 2001. Anatolian Tree Rings and a New Chronology for the East Mediterranean Bronze-Iron Ages.Science, 294(5551):2532–2535. Available at: http://www.sciencemag.org/content/294/5551/2532 [Accessed May 25, 2015].
Nowviskie, B. 2011. Where Credit Is Due: Preconditions for the Evaluation of Collaborative Digital Scholarship. Profession, 2011(1):169–181. Available at: http://www.mlajournals.org/doi/abs/10.1632/prof.2011.2011.1.169 [Accessed May 25, 2015].
Plicht, J. van der, H.J. Bruins, and A.J. Nijboer. 2009. The Iron Age Around the Mediterranean: A High Chronology Perspective from the Groningen Radiocarbon Database. Radiocarbon, 51(1):213–242. Available at: https://journals.uair.arizona.edu/index.php/radiocarbon/article/view/3486 [Accessed May 25, 2015].
Rabinowitz, A. 2014. It’s about time: historical periodization and Linked Ancient World Data. ISAW Papers, 7(22). Available at: http://dlib.nyu.edu/awdl/isaw/isaw-papers/7/rabinowitz/.
Shanks, M., and R.H. McGuire. 1996. The Craft of Archaeology. American Antiquity, 61(1):75–88. Available at: http://www.jstor.org/stable/282303 [Accessed May 24, 2015].
Shapiro, C., and H.R. Varian. 1999. Information Rules: A Strategic Guide to the Network Economy. Harvard Business Press.
Sharon, I., et al. 2007. Report on the First Stage of the Iron Age Dating Project in Israel: Supporting a Low Chronology. Radiocarbon, 49(1):1–46. Available at: https://journals.uair.arizona.edu/index.php/radiocarbon/article/view/2898 [Accessed May 25, 2015].
Shaw, R., et al. In Press. The Sharing-Oriented Architecture of the PeriodO Period Gazetteer. International Journal on Digital Libraries.
Schloen, J.D. 2001. Archaeological Data Models and Web Publication Using XML. Computers and the Humanities, 35(2):123–152. Available at: http://www.springerlink.com/content/jk1q91115506k6j5/ [Accessed December 16, 2009].
Shott, M. 2014. Digitizing archaeology: a subtle revolution in analysis. World Archaeology, 46(1):1–9. Available at: http://dx.doi.org/10.1080/00438243.2013.879046 [Accessed May 25, 2015].
Tudhope, D., et al. 2011. A STELLAR role for knowledge organization systems in digital archaeology. Bulletin of the American Society for Information Science and Technology, 37(4):15–18. Available at: http://onlinelibrary.wiley.com/doi/10.1002/bult.2011.1720370405/abstract [Accessed May 26, 2015].
[1] See: http://www.perseus.tufts.edu/
[2] See: http://pleiades.stoa.org/
[3] See: http://arachne.dainst.org/
[4] See: http://www.fastionline.org/
[5] See: https://finds.org.uk/
[6] See: http://pelagios-project.blogspot.com/
[7] See: http://www.cidoc-crm.org/
[8] Open Context primarily uses Creative Commons Attribution copyright licenses and Creative Commons Zero public domain dedications for content, these measures together with offering machine-readable data make it an “Open Data” publisher.
[9] Open Context’s new APIs are documented here: http://opencontext.dainst.org/about/services
[10] See an example in Open Context: http://opencontext.org/subjects/1E756B14-0EB8-46B5-1FFD-EEFD4ADE9F97
[11] See: http://openrefine.org/
[12] See: http://ark.lparchaeology.com/
[13] See: http://heuristnetwork.org/
[14] See: https://www.fedarch.org/
[15] See: http://catalhoyuk.stanford.edu/
[16] See examples Mantis: http://numismatics.org/search/ and Nomisma: http://nomisma.org/
[17] See: http://ads.ahds.ac.uk/arena/