Since I won’t have time to talk about this in detail during my ten minute bit for our Future of Classics discussions, I thought that the blog might be the appropriate forum to pre-emptively follow-up (if such time travel is in fact possible) on a point which I will make tomorrow about what can be done in with relative speed and ease using data and tools that are already available out there. I suspect that many have seen Wordles, representations of word frequency data (raw or relative) that allows you to appreciate, at a glance, which words (and by extension, ideas) might matter more, at the macro-level, for a particular text or set of texts. (Clouds like this are relatively common on websites to show popular tags and search terms of course.) Some may have even seen variations of this for Homer. Here’s Martin Mueller’s Wordles for lemmata more common in Homer’s Iliad vs. the Odyssey and, conversely, more common in the Odyssey vs. the Iliad:


And, since these take under 2 minutes to create as long as you have the statistical data, here’s one I just did for Euripides’ Electra relative to Sophocles’ Electra (i.e. words that occur more often in Euripides’ play relative to their occurring in Sophocles’ play)

And here’s the converse, Sophocles’ play relative to Euripides’ play:

Now, there are some surface observations which may seem like what we already know– e.g. that Electra in Sophocles’ play is onstage being wretched all the time, she’s stuck at home, etc. But why φθόνος? For any word there are questions which should send us back to the text— does this statistical difference matter at the micro-level of the play?
Once we have the data separated out by speaker (which was a prerequisite for the text mining work), then the options for doing even these simple visualizations multiply quite rapidly. So, for example, here’s speech in the Iliad vs. narrative in the Iliad, and it’s about what you’d expect:

Lot’s of I, you, and us talk. But compare the Odyssey (same thing, speakers vs. narrative)

The φίλοι might be pretty obvious– but there are still plenty of things that should raise questions as to what precisely is different and where such differences, manifest here only at the statistical counting words level, might make themselves felt in specific moments of the text (and of course, they may not be meaningful. Much is a function of situation and the story of course.) The point, such as it is, is that this serves as invitation to reinvest in the poem with particular questions (why is x word so much more common here rather than there) that emerge from viewing the poem in a different and immediately graspable way.
But this only scratches the surface of what is out there. Not all of these work with Greek (and not all are necessarily suitable to Greek or Latin language structure), but there are some powerful tools out there that classicists might find incredibly useful. So, for example, historians can use arc diagrams to look at Jefferson’s letters or look at key terms in London court documents. Or we can see some of the trends in particular area of scholarship. For any one interested in how words in a text relate to other words, there are a great variety of tools for visualizing English. A key principle in the development of these tools is that they can be a starting point for investigating all sorts of data. For that to happen, data needs to be available and so it is not coincidental that some of the most striking displays of the power of these sorts of visualizations use vast quantities of public data linked up and pulled from various sources. (For the way the next web might link structured data, I direct you to Neel Smith’s post on Tim Berners-Lee’s TED talk — with video– and, in case you haven’t seen it, you should check out Hans Rosling doing 200 years of history in 4 minutes as illustration.)
In addition to the text-mining tools I have been working with, I have been necessarily interested in other tools. Most such tools aren’t made to work with Greek, but one of the striking things I’ve been finding with the text-mining work is (though it seems obvious in retrospect) the non-importance of paradigms. That is, we moderns tend to learn ancient languages as a series of paradigms, i.e. hierarchical structures where what matters is the lemma moreso than the specific form. But that is not exactly native language learning and the importance of this difference comes through in looking at language use. I’m not a linguist, so I’ll leave it to them to go into further detail. But at a very practical level, when running data mining tests on tragedy and on homer, it is striking how adding lemma information tends to reduce the meaningfulness of results. By contrast, it is in fact most useful, so far, to run tests using the completely naive level of words without reference to our sense that a dative form of a particular word is most closely related to other forms (nominative, accusative, genitive) of that same word. Similarly, as a philologist, it feels natural to focus at times on rare words or on words that semantically feel like they have a lot of meaning in a particular text. There is of course good reason for this, but — this is obvious to linguists and anyone interested in deixis– there is a great deal of information conveyed in the little words, i.e. the various “me”, “I”, “this”, “that”, and so forth. This is all great news for using visualization tools as it means that we may not need (or it may not be worth the effort) to shape them in language-specific ways (that is, by taking account of morphology). With that in mind, I’ve been trying out the Voyeur Tools utilities developed by Stefan Sinclair and Geoffrey Rockwell along with IBM’s Many Eyes. I give 3 examples below with a few preliminary remarks.
1. Athenaeus using Voyeur Tools: Using publicly available Perseus texts converted to unicode, I uploaded these into voyeur tools. (You can access it here.) I haven’t cleaned up the text in any way, but it goes book by book and some simple searches for author names (use partial author names, with accents, in greek font, separated by commas to limit the word list) can give you graphs which will overlay frequency of those authors (i.e. where they are named) over the course of the work. Interesting is, on a preliminary scan, that certain authors follow each other quite tightly (e.g. Aristophanes and Eupolis). More interesting is that the frequency of mentioning these authors is inversely related (again, on a very cursory sweep) to certain middle comic poets. Are there other correlations like this? I invite others to see what they can find, with the same principle at work for the Wordles above. These are not conclusions or even the results of searches, but rather a particular way of looking at our data (in this case all the words in Athenaeus, divided by book) with fresh eyes. The goal then is not to shut down any interpretation (i.e. statistics shows x) but rather to prompt new questions. Of greatest consequence is that something like this takes shockingly little time– on the order of a half hour from downloading the Perseus xml (in beta code) through a quick conversion scheme and then feeding them into the tool.
2. Homer and Apollonius
Using the same Voyeur Tools package, you can use a scatterplot to take a lot of that complex data and show it in more user-friendly form. So, here’s Homer’s Iliad, Homer’s Odyssey, and Apollonius, all similarly with unedited Perseus texts for the Greek. I also haven’t removed stop words (i.e. the most common greek words) or done anything else to this data. Now, this may or may not mean anything, but the graphical view again helps expose relationships which may not be so obvious from the raw numbers. Not surprisingly, Apollonius is removed a bit from the two Homeric poems, but more interestingly, what is nearest to the poems is more closely correlated with that work. So, it is not surprising but still reasonably interesting that ἔτι should be so tight to Apollonius (relatively speaking). Is it that Apollonius uses the term differently as well as simply more frequently? But for Homer there are potential questions as well– why, for example, is αὐταρ so much more frequent in the Odyssey than in the Iliad; that it is Homeric is familiar, but is there anything to the Odyssean preference? As this is a dynamic tool, you can explore it relatively easily, but again my point is not so much to make an argument about Homer or Apollonius as to show that this is a means for generating questions and invite you to take a look at it.
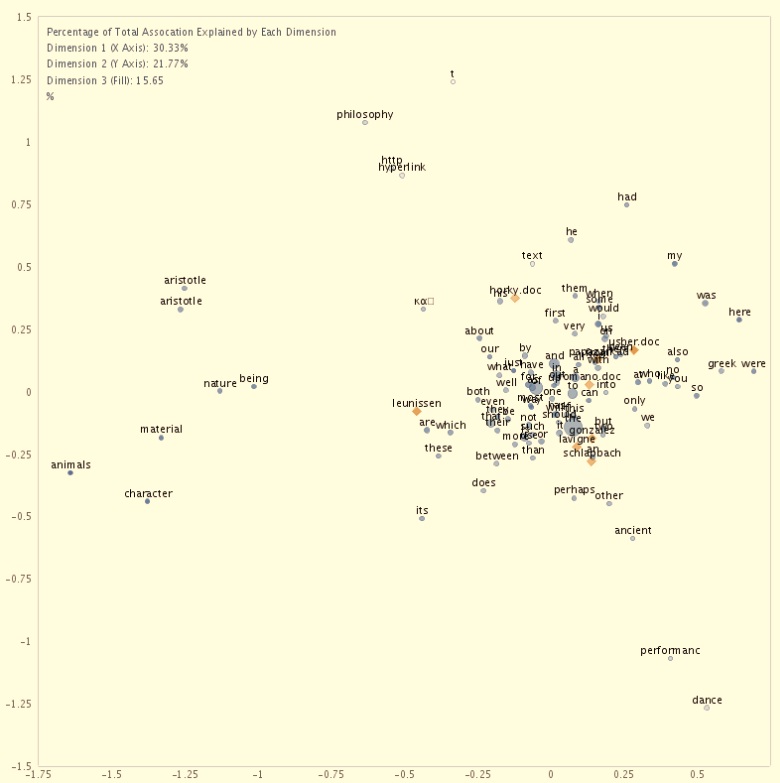
3. One final example, because it seemed an obvious thing to do. I fed our blog posts here into these same tools. I’m not going to post the link to this, but among other things, I found out that I have among the longest and shortest posts (not surprising) and that I have the second-highest word density. (not so sure what to make of that). Rather than detail further idiosyncrasies of our individual blogging habits, I will simply give you one view of the correspondence analysis. (texts are yellow diamonds, words are blue circles; shading indicates a third dimension; it only includes the largest files, so not everyone is represented here. more significant, this is raw text, no manipulation for key words or themes– that analysis would be more immediately relevant, but would also have taken longer than 10 minutes of cutting and pasting, which is the limit I set for myself on this.) At one level it tells us something we know– namely that Phil and Mariska talk philosophy where others don’t (at least not as much.) That’s what all that philosophical stuff is doing out on the margins. But there is also a dense cluster of Don, Jose, and Karin. I’m off to the north, Nick a little north of that, and then Mark a bit north of that. Seems a reasonable enough plotting of the affinities among the various posts and writers. But it might tell us too a bit about each of our specific language use– for example– “text” occurs relatively often– but why is it so far away? Anything else leap out?